


Data-Centric AI Case Study: Improving Model Accuracy by Only Cleaning Data
When we first start in machine learning, we're excited at the prospect of creating models and algorithms. We're drawn in by the seemingly magical features these models can unlock in our applications.
Then, relatively soon after we begin, we hear or read something along the lines of:
Data science is 90% collecting, cleaning up, and labeling data and 10% creating algorithms and training models.
Wait, what? That can't be right. Data science is supposed to be fun and glamorous! It's the new(ish) hotness! What's the point of machine learning, if we have to do so much manual work?
Paying close attention to the quality of your data is the main principle behind data-centric AI. We keep hearing more and more stories about inaccuracies in open datasets and how correcting them improves the quality of the models trained on them.
This blog post is part of a series on data-centric AI and active learning. In our previous article, we gave an overview of active learning techniques and their advantages.
In this post, we’re going to show how important data quality is. We'll be training and comparing four squirrel detector models. Each successive model will incorporate another round of data clean-up. We're going to see for ourselves what a difference data-centric AI really makes!
Why squirrels? Because who can resist a cute, cuddly squirrel?

Model 0 - Lazy Data
For our first (zero-th?) model, we need a baseline. We're going to scrape DuckDuckGo for images of squirrels using a simple script. Each time this script is run, it will download up to 1,000 images for the query we give it.
We're going to try three queries, meaning we'll have at most 3,000 images, with which to train a model. The three queries will be:
- squirrels - 557 images
- backyard squirrels - 732 images
- field squirrels - 473 images



Why don't we have 1,000 images for each? When scraping images from DuckDuckGo's image search, many images may have broken links, temporarily down, or animated gifs. The latter we just remove for simplicity. So it’s not 3,000 images, but who cares? That's enough to start!
Now we’ve got data, but no labels. If we were training a classifier, that would be easy… but we want to train an object detector. We need bounding boxes. Unfortunately, that can be a lot of boring, mundane work.
However, since we’re smart, resourceful software developers, what if we just run our images through a model pre-trained on the COCO dataset?
I know what you’re thinking. COCO doesn’t have a squirrel label. If it did, we wouldn’t have to train our own squirrel detector. Look, we all know that… but does a YOLOv5 model, pre-trained on COCO, know that it’s not supposed to know what a squirrel is?
Interestingly enough, if you run images of squirrels through a model trained on COCO, it kinda gets it right. It doesn’t know what a squirrel is, per se, but it does recognize their “animal-ness”.

All we have to do for our initial data labeling:
- Run inference on all our scraped images
- Map the animal categories (bird, bear, sheep, etc…) to a single class
To run inference, the YOLOv5 repository has a handy detect.py, we can use to get our initial set of labels. We can run this script with the following command:
> python detect.py --weights yolov5s.pt --source /path/to/images --save-txtThese parameters are:
- weights - starting with a pretrained small version of YOLOv5
- source - path to a single image or a directory of images
- save-txt - save the inference results in YOLO-style text files (one text file per image)
After running, the results are under yolov5/runs/detect/exp/labels/.
Check out convert_labels.py for an example of how to map the classes in these YOLO-style label files.
After following the two simple steps, we have our initial dataset. We can now train our baseline model!
If you’re interested in training your own model, you can find this dataset under the squirrel0 branch in the repository.
We'll use the following command to train our model:
> python train.py --weights yolov5s.pt --seed 42 --batch-size 32 --imgsz 640 --data squirrels.yaml --epochs 300
The parameters from the above example are:
- weights - starting with a pretrained small version of YOLOv5
- seed - give all runs the same seed to make model comparisons more valid
- batch-size - 32 images per batch
- imgsz - use 640x640 pixels as the input image size
- data - yaml file describing the location of our dataset
- epochs - run for a maximum of 300 epochs
These models were trained on an NVIDIA GeForce RTX 2080 Ti, which has 11GB of VRAM. However, it can also easily be run on a CPU, but will take a few minutes per epoch to run.
Now we wait for training to finish.

Looking at the results, from our training and validation sets we see:
| Dataset | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|
| train | 0.776 | 0.739 | 0.797 | 0.514 |
| val | 0.784 | 0.737 | 0.797 | 0.504 |
Here we are looking at 4 metrics:
- Precision - measures how many of the predictions are relevant objects
- Recall - measures how many of the relevant objects are correctly predicted
- mAP@0.5 - mean average precision measured with an IoU (intersection over union) of 0.5
- mAP@0.5:0.95 - mean average precision averaged for IoUs ranging from 0.5 to 0.95 in 0.05 increments (i.e. calculate mAP@0.5, mAP@0.55, mAP@0.6, … mAP@0.95 and average the results)
We have our start… It’s not bad at all, but there’s room for improvement!
Model 1 - Remove Obviously Bad Images
Ok... when we take a cursory glance through our downloaded squirrel images, we immediately spot a problem.
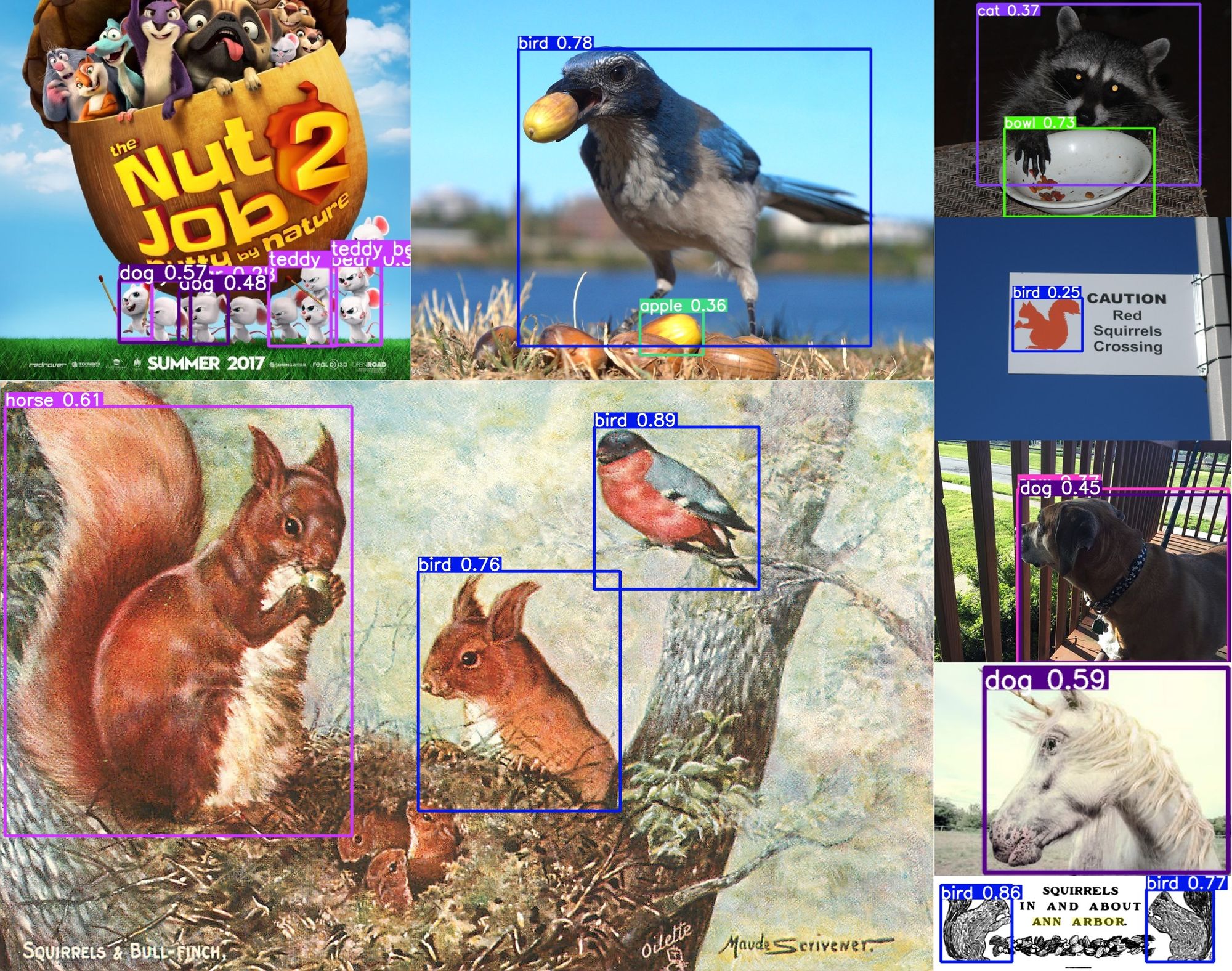
The problem with actual images of birds, dogs, and other objects incorrectly labelled as such is that our script converts those labels to squirrel labels. That’s going to certainly confuse our model when it comes time to train!
Cartoon images of squirrels are also not super helpful when trying to detect real-life squirrels.
An easy clean up step would be to go through and remove images that are low resolution, obviously not squirrels, or cartoon images of squirrels.
Even though going through 1,762 images sounds like a lot of work, it goes by pretty quickly when you're just looking for these really bad ones. It shouldn’t take too long.

After we've removed those images, we have a dataset with 427 images. We just deleted about 76% of our dataset! That was a ton of bad data! Maybe we shouldn't implicitly trust search engines? 🤔
This dataset can be found in the squirrel1 branch of the repository.
It's time to train our 2nd ML model, which should go much more quickly now that the dataset is smaller.

Let’s look at how these changes affected our model’s accuracy.
| Model | Dataset | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|
| 0 | train | 0.776 | 0.739 | 0.797 | 0.514 |
| 0 | val | 0.784 | 0.737 | 0.797 | 0.504 |
| 1 | train | 0.819 | 0.754 | 0.804 | 0.469 |
| 1 | val | 0.853 | 0.725 | 0.810 | 0.468 |
You can see that we improved precision by a good amount, but had a small regression in our recall metric. Since the validation sets are the same, this means we had less true positives but also less false positives.
One potential explanation may lie in how YOLOv5 initially labeled some squirrels. If you look at the image above with examples of how a COCO-trained YOLOv5 model interprets squirrels, occasionally, it would add a bounding box for the body and a second for the tail. These would count as two relevant objects.
If the data removed helped our model focus on just the squirrel as a whole, then it may only return a single bounding box instead of two. When compared to a ground truth of two bounding boxes, it would decrease the recall and the mean average precision at higher percentage values (mAP@0.75 for instance). This in turn, would decrease our mAP@0.5:0.95 metric.
Model 2 - Remove Duplicate Images
That wasn't too bad, was it? But there's more work to be done! You may have noticed, our dataset has a bunch of duplicated images in it. Duplicated data can be bad for a couple of reasons:
- Repeated images causes the model training to focus unevenly on those samples compared to other unique samples.
- Duplicate images can end up in your validation or test set, causing the model's accuracy to be artificially inflated.
Now, being software developer looking to automate as much as humanly (computerly?) possible, we don’t want to manually find the duplicates.
We could try using diff, but that will only work if two files are exactly alike. Images can be duplicates without having the exact same bits in their files. For instance, an image may be recompressed or scaled down.
Luckily, we can turn to machine learning to help us! 🤖
We can use a pretrained ML model to extract the feature embeddings for each image and then compare those embeddings using a cosine similarity function. Cosine similarity tells us the cosine of the angle between two vectors (or feature embeddings). The closer the internal angle is to zero, the more similar they are, since \(\boldsymbol{cos(0) = 1}\).
Using a script like dedup.py we can identify duplicates and then remove them after verifying. This script uses EfficientNet V2 (small) to extract feature embeddings for the images and a function from scikit-learn to calculate a matrix of cosine similarities between all embeddings.
After running this script and deleting the duplicates, we now have 309 images left in our dataset.
This dataset can be found in the squirrel2 branch of the repository.
Time to train our 3rd model!

And after that’s done, our results look like:
| Model | Dataset | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|
| 0 | train | 0.776 | 0.739 | 0.797 | 0.514 |
| 0 | val | 0.784 | 0.737 | 0.797 | 0.504 |
| 1 | train | 0.819 | 0.754 | 0.804 | 0.469 |
| 1 | val | 0.853 | 0.725 | 0.810 | 0.468 |
| 2 | train | 0.965 | 0.710 | 0.856 | 0.542 |
| 2 | val | 0.874 | 0.768 | 0.844 | 0.526 |
This time all metrics improved across the board! That’s what we like to see!
But can we do better?!?
Model 3 - Fixing and Fine-tuning Boxes
Ok. We’ve taken care of the easiest forms of data clean up. The only thing left is… manual labor 😱
This will be, by far, the most time consuming part of the data cleanup process… but it will also be worth it. Luckily, during the first couple of stages, we removed 1,453 images, so we have significantly less data to manually clean up! That sounds like a big win.
To help us clean up the data, we’re going to use Label Studio, an open source data labeling tool. It has a nice web-based interface that allows us to quickly add, delete, and tweak bounding boxes. Additionally, when we use DagsHub’s integrated version, we:
- don’t need to move the data to a 3rd-party platform
- can easily export these labels into a format compatible with YOLO (or others!)
Importing the YOLO-style labels into LabelStudio is a bit of a manual process right now. But if you look at yolo2labelstudio.py you can get a feel for how to do it fairly easily.
We’ll run that script on both the training and validation datasets and then push the changes to our DagsHub repository. Then once we’ve created a Label Studio workspace, we can go through and graphically view and change our annotations.
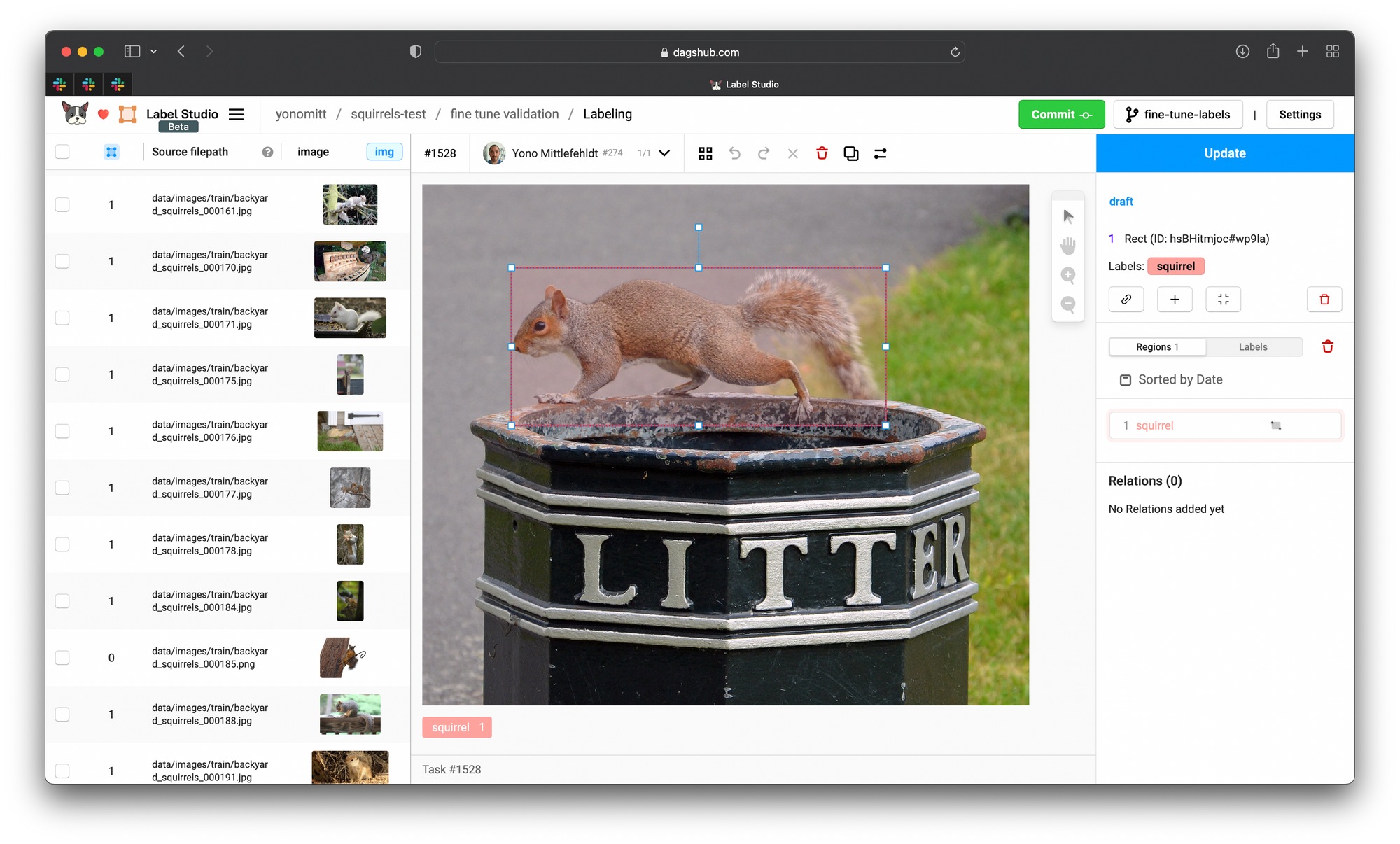
After fixing incorrect bounding boxes, merging overlapping ones, and adding missing labels, we can export our YOLO-style labels.


This dataset can be found in the squirrel3 branch of the repository.
Now we're ready to train our 4th and final ML model!

From here we can see some much improved results:
| Model | Dataset | Precision | Recall | mAP@0.5 | mAP@0.5:0.95 |
|---|---|---|---|---|---|
| 0 | train | 0.776 | 0.739 | 0.797 | 0.514 |
| 0 | val | 0.784 | 0.737 | 0.797 | 0.504 |
| 1 | train | 0.819 | 0.754 | 0.804 | 0.469 |
| 1 | val | 0.853 | 0.725 | 0.810 | 0.468 |
| 2 | train | 0.965 | 0.710 | 0.856 | 0.542 |
| 2 | val | 0.874 | 0.768 | 0.844 | 0.526 |
| 3 | train | 0.958 | 0.826 | 0.920 | 0.709 |
| 3 | val | 0.964 | 0.812 | 0.917 | 0.693 |
Once again, all the metrics for our validation set got better. These are the kinds of model improvements we dream about! The large improvement to mAP@0.5:0.95 is especially welcome. It hints to the fact that our bounding boxes became significantly more accurate over the previous runs.
Data-centric AI FTW!
What We Have Learned
Despite often being tedious, mundane, and grueling, data clean up is extremely important. The quality of our models greatly depends on it. This is the main takeaway from data-centric AI.
We've also seen that we can write some simple scripts to help us in our herculean clean-up efforts. So although it wasn’t all manual, it is important to be smart about when and how you automate data clean up. Our last step, which was also the most manual one by far, provided the most improvement.
In a future blog post, we're going to delve further into data-centric AI by improving our squirrel model using Active Learning. We'll even use our 4th model from this blog post to begin the active learning training cycle.
Stay tuned!
If you have any comments or questions, feel free to reach out!


