Every software comes with issues & errors. No software can be defect-free and it is one of the guiding principles behind testing any product. It will be impossible, even theoretically, to identify all defects in software. Hence a tester would prioritize itself to find the most important defects early.
When it comes to AI, most of QA professionals stumbled to get across product quality information out of it. This is due to difference in nature of building AI applications as compare to traditional products.
developers and data scientists would say – “we don’t need to test quality , we already have accuracy metrics in place to verify outcomes.”
Is testing of AI software only restricted to model accuracy metrics? Definitely not.There are loads of ways AI software can fail – and in this post we are going to list some of the most common ways they fail.
Understand this A machine learning algorithm can never work in isolation, in fact it’s a small part of whole system. Like a human body. We can use various heuristics and quality parameters to test all body parts – because each one does some very specific tasks. Now, given the assignment, how will you go on testing brain of human body? ( or for that matter a machine learning feature which learns and gets better? )

I won’t be covering issues related to other blocks as of now. And all issues related to small ML box will be impacting system functioning as a whole. It would be worth looking at how the ML part fails, have some limitations or susceptible to failure.
10.Interpretation of machine learning results is difficult to impossible
Machine learning Systems, especially, ML blocks do have testability limitations. Most machine learning models are difficult to interpret, meaning we would not know why the application is giving specific results. This is especially true for popular Deep learning algorithms. There are some tools like this that help interpretability, however, we still don’t have a robust solution for model explainability. In fact, this is one of the research areas in Artificial Intelligence. Few algorithms like decision trees are helpful, but they aren’t stable too.
This limitation makes machine learning systems weak contender to implement in enterprise applications where stability and robustness of application is major concern.
9.One model doesn’t work for other types of predictions
We build models based on the data we have. And this model gives results only on a “similar” dataset. Change the data and boom! model and application will start throwing error.
All models learn from a specific dataset. And they aren’t flexible enough to work on different datasets. In fact, this is a research problem and we are far away from solving it yet.
8.ML model fairness
Model fairness is my favorite subject. In a famous example, AI chatbot built by Microsoft learns to tweet based on what users were tweeting about. And the results were horrifying.

There is another example from Amazon recruiting tool. This is similar to Garbage In, Garbage out principle. So Project Managers will definitely required to keep a watch on nature of data we are training on.
7.Results are sometimes better than tossing coin
In one of the projects I worked on, where I need to predict if the employee would leave the organisation or not (attrition) – I got 40% accuracy. This is after months of research into data, feature engineering, and state of art machine learning algorithms.
If I ask a monkey ( no offense to monkeys) to predict if someone will either “go” or “stay” in the organisation – he would also get 50% accuracy. Or I could just toss a coin. Heads -you stay, Tails-you go.
6.A 99.99% accurate model
A data scientist knows if he shows 100% accuracy of model , either he has done a mistake while model training or if not, there is actually no need of Machine learning technology in that kind of problem. What if he gets 99.99% accuracy?
Even, most of the time – this is also an case of over-fitting. Model has learnt too much from existing datasets that it simply won’t work correctly on new data that he hasn’t seen yet. Best of models I have seen yet falls between 70%-80% range of accuracy, though it’s not the rule. In Deep learning applications of images/videos/text datasets, accuracy falls in ranges of 50%-60% .
By the way, in past I had clients who expected 100% accuracy on models. We had to say no to them while explaining that even theoretically it would not be possible.
Even if your model has one of the best accuracy percentages, we need to connect the dots to real world problem.Here is the real world problem where things get serious.
5.High CPU, GPU usage
Machine learning systems tend to take a much larger piece of overall resources you have while development and productions. As all models use “statistics” to find patterns within data & do complex vector operations on large matrices, it would require a large GPU, lots of memory. If you have continuous training enabled, it would take more memory.
This is called as infrastructure debt. You can read more about various debts that Machine learning systems has.
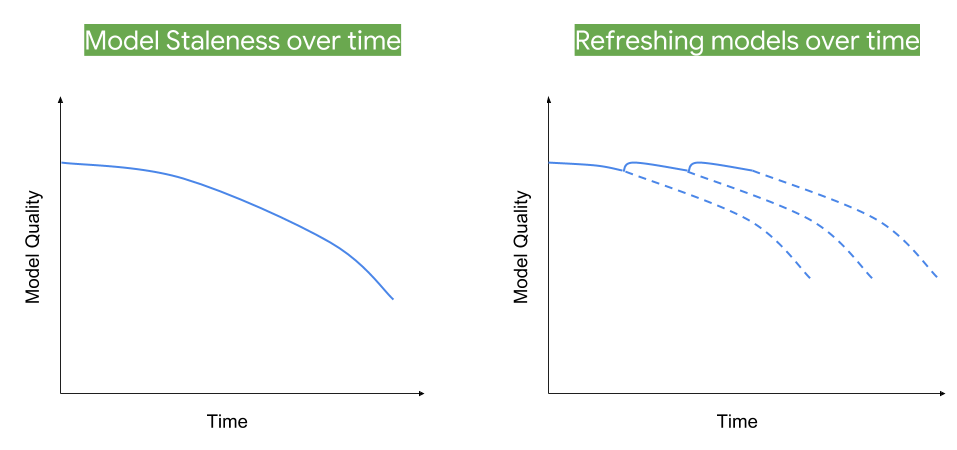
4.Suddenly dropping results
Your production ML model would suddenly start producing bad results after some time. Finding out the reasons behind it won’t be straight forward. Maybe your model has become stale, may be input data from the real world is quite different than previously anticipated and we haven’t put on unit tests to identify them.
Dissecting the model would take a long time – depend on if you have structured datasets models or deep learning-based models. Many times you won’t get this much time to identify the root cause and you would prefer building a new model again.
3.Different results for same inputs
For the same data inputs, your model ideally should give the same results every time data passes through it. This is not the case always in reality.
All ML models are not deterministic but are Stochastic in nature.
A deterministic system doesn’t possess any randomness. All parameters are fixed, logic to results are fixed and everything is pre-defined. ML models don’t have this luxury. ML system behavior strongly depends on data and models that can’t be specified a priori.
2.High maintenance & technical debt
Not only Infrastructure debt, but Machine learning systems are also a high-interest credit card of technical debt. Data dependencies cost, Data Pipeline Jungles, Configuration debt are some of the important debts. For full list of technical debts introduced in ML systems see here.
1.You can fool model easily.
As major logic is hidden in “data”, machine learning systems can be fooled, quite easily by just manipulating data. If the system is accepting input data from production as is, it is susceptible to failure or hacking. The earlier example of a Twitter bot built by Microsoft is something that model has learned,which it shouldn’t. My previous blog post about Toaster is adding noise data into neural network model training and fool the model easily. Adversarial attacks on ML systems possess a big threat.
Fast gradient sign method, an approach of manipulation by adding or subtracting small error to each pixel, in order to introduce perturbations to the datasets, resulting in miss classification. If the model depends on such datasets, such as Face recognition systems, personal identification systems can be attacked easily.
Ending my blog post here. There could be a lot more issues in ML systems which I missed here. Please comment below if you know some.
In next blog post , we would look at prerequisites for a testing any AI system.
References:
- https://www.theverge.com/2016/3/24/11297050/tay-microsoft-chatbot-racist
- https://medium.com/thelaunchpad/how-to-protect-your-machine-learning-product-from-time-adversaries-and-itself-ff07727d6712
- https://analyticsindiamag.com/how-to-fool-ai-with-adversarial-attacks/