
So this happened…I had the privilege to attend the Google Webmaster Conference Mountain View: Product Summit on November 2, 2019. First off I want to say a huge THANK YOU to the Google team for allowing me to go. Secondly, I wanted to make sure I captured any nuggets that might be valuable for the SEO community in the spirit of learning.
Table of Contents
What is the Google Webmaster Conference Product Summit anyway?
The Google Webmaster Conference Product summits are, “a series of Webmaster Conferences being held around the world to help website creators understand how to optimize their sites for Search.”
Their goals are simple:
- facilitate dialogue between the webmaster / SEO community and Search product teams
- an opportunity for SEOs to give feedback and learn about how the product team thinks about search
Needless to say after applying I was ECSTATIC to get the following email:

The schedule:
Here was the general schedule of the day:
- 9:00AM – check in, breakfast
- 10:30-12:00 PM – lightning talks
- 2PM – 2:45 PM Improving search over the years
- 2:45PM – 4:00 PM Product fair (speaking with specialist product managers about their search feature)
- 4:00 – 4:45 PM – Fireside chat
Highlights from the Google Webmaster Conference:
Opening talk:
- Google holds monthly ranking fairs for the search teams – basically show and tell opportunities for Googlers to explain and collaborate on search-related projects. A cool idea to spark cross-team collaboration
- Google sends over 24 billion visits/month to news publishers
Lightning talks:
No Googlers mentioned per their request 🙂
Product Manager, Search on Structured Data
- Evolution of search – moving from 10 blue links to have a richer experience using things like carousels and meta data, these are all powered by structured data (using recipes as an example)
- Structured data gives hints to Google to help them understand content better
- Makes your pages eligible to appear in rich results, and appear in page-level features (recipes), be visible in search experience and works on Assistant
- Use this link to see all the ways you can use structured data
- Measure their performance and implementation in search console with the Rich Results Test
Software Engineer and PM for Search Console
- The teams mission is to provide data & tools to help site owners improve their website in ways that improve their appearance in Google
- How do we improve websites?
- Step 1: Define what can help a page succeed – mobile friendliness etc. If a website tries to implement things like structured data to help is it implemented correctly?
- Step 2: Classify all the pages in the Google index and annotate any issues
- Step 3: Help site owners fix their site, by using the UI and emails. Once you fix it, you can let them knows its fixed and that starts validation process to see if the fix was implemented correctly
- How search console works – 5 main components 1) search analytics from google search results, 2) reporting 3) testing tools, 4) account and 5) alerts
- Search Analytics – track all impressions on search, gives those insights to you for 16 months
- Reporting- track all pages crawled, 100s of signals support dozens of search features and give you actionable reports
- Testing Tools – trigger the Google index stack for any given URL, on demand for any URL, very high fidelity to search to enable your debugging
- Accounts – security a big concern, want to protect data via validation and enable easy monitoring
- Alerts – what triggers emails? If they see anything that requires your attention they’ll send you an email (they have 10s of report types)
- How we created the speed report (launching today) biggest issue was how do you define a fast page? What Googlebot sees is different than what end user sees. So they used Chrome experience user reports since it shows user experience all around the world
Web Deduplication
- What is it? Identify and cluster web pages that looks the same, take the clusters and choose representative urls that get shown to users (canonicals)
- Why they do it – Users don’t want the same result repeated, it gives more room for distinct content in the index so you can handle long-tail, it’s good for webmasters because you retain signals when redesigning your site and we can also find alternate names (synonyms)
- Clustering – redirects, content, rel = canonical and others, “We largely trust redirects, as they are almost perfectly predictive of duplicate content”
- Content – use content checksums, Google makes efforts to ignore boilerplate content and catches many soft error pages (like when sites go down for maintenance) please serve 500s instead of a 200 since Google thinks all your pages disappeared/are empty
- Rel=canonicals gets fed in to clustering, if you use your annotations to cluster they tend to get more verification. Thresholds are still intentionally loose because people make mistakes and there’s often broken scripts
- Localization – When main content is the same, pages are clustered. This can include boilerplate-only localization. Clever geo-redirecing often also clusters (in this case Google wants you to tell them what to do with hreflang because to them you sent them the same page)
- Canonicalization – their biggest goal is to avoid hijacking (role number 1) escalations via WTA in the forums are a great source, second concern is user experience. Third is webmaster signals: redirects, canonicals, sitemaps

Product Manager, Google Images
- Launched a lot of aesthetic changes to improve legibility and more prominent CTA buttons
- Recently for AMP – launched swipe to visit to reduce friction to visiting the site
- Optimization best practices – use structured data for rich results (esp. for products, videos, recipes). Use descriptive titles, captions and file names, we surface those to the users
- Use high quality images, they want to show “beautiful and inspirational content”
- Mobile-friendly pages = all that leads to better results
- Check image search traffic in search console (Search Type: Image)
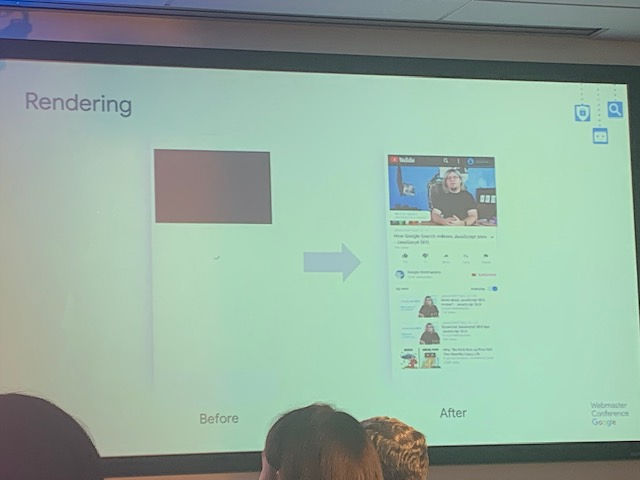
Rendering
- Rendering allows Googlebot to see the same web as users do
- Rendering basically needs to behave like a browser, that’s both complicated and expensive. Good thing they have a great browser – so Google renders with Chrome these days
- Chrome renders page, loads additional content, Googlebot fetches that content on behalf of Chrome, once its loaded they take a snapshot of the page and thats what gets indexed to the web
- Gets interesting at scale, trillions of pages in the index. Mainly because of 1) fetching the content and then 2) running the javascript, its a lot of new logic
- Fetching is the more difficult problem. Mainly because of limited access to resources (robots.txt) and limited crawl volume, they want to be good citizens and have a reasonable crawl volume so they don’t cause server issues
- This means on average they do 50-60 resource fetches per page (obeying robots.txt), which is a 60-70% cache rate, other benefits are it helps them avoid ad networks etc. Crawl costs go up by about 20x when you start rendering. So they cut corners – big one is http caching. Most people are too conservative and so Google ignores and over-caches, the best way to cope with this is to not rely on clever caching tricks, this is good for users and Googlebot
- Javascript – good news is they’re running Chrome so the environment is good. Bad thing is theres a lot of js and they need to run a lot of it. Google is constrained with CPU globally, so they want to make sure errant pages don’t waste resources. They will interrupt scripts if they’re wasteful (in extreme cases they’ll mark it un-renderable)
- Most pages are OK. But popular issues: error loops (robots.txt, missing features) cloaking, cryptocurrency miners they’re VERY heavy and made the indexing explode several times
Software Engineer- Core Ranking in Search Title and Result Previews
- Result preview team pillars: Relevance – largest task user has is to find the page they want to consume. what preview could be generated that would help them make the choice? Also want to illuminate the depth of content in a website, and express diversity of content in the ecosystem
- Images help users to choose – images are to the right of the title because they’re secondary to the title/snippet. Galleries support contentful pages, this helps users visits a greater diversity of sites
- Sitelinks – Links are relevant to query, links to pages to your site that Google thinks are relevant to the user, these are extracted algorithmically (occasionally structured site helps) Sitelink images pithy links are better understood
- Entity Facts in previews – relevance to needs around the entity, extracted algorithmically (tables, lists)
- Forums – many don’t have structured markup. They want to show users its a forum so they can ensure the forum cluster is relevant to the query, users find value in this yet forums rarely use markup so be sure to use markup (Q&A schema takes priority)
- Tables and lists – pages with dominantly placed tables/lists, highlighting these in search results help users understand this is what the content really is about, so the structure and location of the table matter
- Relevance infuses everything, attribution helps user choose the source, they also want to express the depth of content well and want to promote diversity of preview formats
Software Engineer – Googlebot and Web Crawling
- Before google can index the page and serve it, they need to crawl and render
- Googlebot follows links, knows dupe urls to protect crawl bandwidth, and re-crawls to keep index fresh
- Trends: today 75% of sites are HTTPS, 40% of sites hosted by NGINX vs. Apache which was incumbent
- 10 years ago average download time was 800 MS, today its 500 MS. That’s good because servers are faster and Google can consume more
- Same robots.txt do get interpreted differently by different search engines, so they worked with Bing to try and create a standard which is still WIP and are hopeful to really make it a standard
- For every url we crawl, we must first check the robots.txt. We have to fetch the robots.txt but sometimes the fetch fails. A 200 is great, a 404 can also be good because it means theres no restrictions on crawling. If you return a 500, it must be transient if its 5XX multiple times they’ll err on the side of caution and don’t crawl at all
- When crawling robots.txt: 69% of the time they get 200, 5% of the time 5XX response code, 20% of the time the robots.txt is unreachable
- Googlebot has a sophisticated way to determine how fast to crawl a site, they want to be a good citizen and not overload your sever. Set the custom crawl rate in GSC if you need them to slow down. Check out the webmaster article on setting up your custom crawl rate (but you cant artificially inflate it to higher than it is)
- Leave crawling velocity to Google unless you’re being overloaded
Product Managers – Knowledge Panel
- According to studies businesses that complete their knowledge graphs are 2x as likely to be considered reputable by consumers
- Suggest updates to inaccurate or outdated information in your knowledge panel, they’re reviewed by a dedicated team and will update with you on your status
- For local businesses, you can edit basic NAP information, hours etc. Most important part is once they discover you, let them where they go next. Websites, social media presence etc. Also engage searches, some knowledge panels can create content and engage/inform searches on Google (eg. recent news about your location)

Synonym search (not actual name of talk, I was late -__-)
- Searches work by essentially adding a lot of “or” operators to pull in synonyms
- Textual synonyms depend on other query words. Context matters
- [gm truck] = “general motors”
- [gm barley] =”genetically modified” try to understand the whole query in context
- [baseball gm salary] = “general manager”
- Designed to find good search results, hidden behind the scenes mostly
- Buy + sell are synonyms, if someone is looking to buy something something selling it is actually a good result
- For a short time in 2005, Google’s top result for [united airlines] was [continental airlines]. They were writing it [united airlines] => [united OR continental airlines OR air OR airline]
- Learned some words serve similar roles but aren’t interchangeable, consider pairs of searches [united reservations] and [continental airlines] are what they call “siblings” – two words that serve similar purpose but are not interchangeable. People compare synonyms to each other, and they realized there are bad synonyms, were synonymizing (example was “cat” and “dog”) . In this case this happened because of the United + Continental merger
- Some good synonyms were lost as a result, they learned that sign in/sign on were siblings, “address” and “contact” some of these were lost but they were happy with the tradeoff overall
- Understanding pattern of failures can reveal solutions. By not patching algorithmic problems manually, we get more general solutions
- Every change has wins and losses. Happy to land 1/2 win/lose loss ratio
- Non-compositional compounds – words like New York are non-compositional (cant shorthand it as New or York) but shorthand like Vegas, Jersey are valid
- Information retrieval – information retrieval is mostly about matching and counting words. Are the words in the title and body? Are they in links? What is the frequency that they occur? Feels nebulous but the right answer is obvious to the first person trying the query
- Once seen, its obvious there is a general pattern here “fantasy game” is not “final fantasy”
- Language evolves over time – like the emergence of emojis. Search ignored emoji for a long time, but decided to build it in because millions were searching for it even though it didn’t work. Took a year, but needed to know how to do things like handle link processing, autocomplete, spelling, many systems were not ready for emoji
- One of the biggest costs is amount of storage used in our index and how we manipulate the index as we build it
- Duplicate content used to be handled 10% time by someone before in 2003 thought it was an edge case, now they have multiple teams working against dupe content
- How much do stop words matter? Ex. use “for” in titles and urls. Answer: write naturally, make your urls and your titles such that people can parse them easily…certainly for on page content like titles write for readers to understand you our whole job is for us to do matching whether or not the user used a stop word.
- G used to only use unstructured data, now structured data supports rich snippets etc. The ranking side is mostly unstructured, in terms of supervised, unsupervised, semi supervised they do a lot of it, they evaluate everything, maybe more on the semi supervised side of it
- Using BERT for 10% of searches- is that helping with edge cases? Answer: BERT is really quite amazing. Lifting all boats on longer more ambiguous queries
- When geolocation is useful, searching for something inherently local and you didn’t use a location (results for “hotel” show local results close to your location)
- Question: Does Google remember information about urls (bad content, noindex etc) if you improve the page? Answer: we try to judge things as they are, but reputation is often based on historical behavior. A lot of the evidence around people talking about the site like “site XYZ scammed me” the reality is the writer (and me Jackie is guessing Google, too) probably don’t know the site changed owners. There’s a lot of things on the web that don’t change quickly.
- Is computer vision a part of image search? Answer: “We use a bunch of machine learning models” 😀
Fireside Chat with VP and Director of Product Management – Search
- Question about AMP – we have a diff. logged out vs. logged in experience, how can we use AMP for logged in content? Answer: For general logged in stuff thats not going to work, have a thing coming out that will allow AMP content even when served from a cache its served logically from your own domain you should be able to get access to your logged in content
- In the case a page basically loads instantly vs. one thats AMP enabled is there going to be a difference? Answer: In order to get it to actually load instantly vs. fast the only way is to cheat to avoid latency around phone–> server, content is rendered before the user clicks requires a lot of work around privacy-centric way. As long as it has the same UX from a search perspective we’re happy for you to use it and improvements are coming next year
- We also think ads are great search results since like organic results they optimize for quality and quality of user experience. Second part of your question is that they can be more structured, we definitely want to make the pages more structured over time…We want to add more structure and help our users find the right site and you can expect to see more mobile SERP changes to help users
- Principal behind mobile first indexing – is we want to show users what they’ll see when they click. We’ve been careful to roll it out to make sure mobile pages were up to snuff as many people had richer desktop experiences. There are times we’ll still crawl desktop to make sure we’re still ranking sites correctly
- Would it be fair to say implementing AMP is a fix for desktop problems (for mobile)? (Essentially yes) The reason why it’s so beautiful is its literally seeing what the user is seeing. Sometimes your performance problems are not visible to you. You’re not using a CDN, the site is not available to people who are looking for you in other areas, while your own tests might be OK
- You have structured data for jobs, recipes etc but theres no structured data around travel (itinerary, top 10 list etc) answer: suggested to use things like Q&A schema
- Might not be continuing work on web light – the hope is as networks, phones get better there won’t be a need for it anymore
- A lot of companies are pivoting to personalization and you guys are experimenting that as well, how do you plan on viewing metrics as they get more personalized? The content can change so how will that affect your judgement of the site Answer: we need a version that we see when we crawl that content, we wont be logged in so there’s that. As far as metrics, thats why they like to use CRUX (Chrome User Experience) since its a large sample of user data
- Question about content accuracy, I came across a patent called knowledge based trust why was that not rolled out? Answer: We patent a lot of things, that doesn’t imply we’re doing those things. I can’t speak to that patent, our job isto return the highest quality content
- Search Quality Rater Guidelines IS our truth for what is good for our users. But truth is not in the rater guidelines, we’re not asking them to know if it’s true, we want to know if it’s trustworthy. We build our algo based off what a normal person would think about quality guidelines
- Indexing API is important to us because there are some things we cant crawl well. Example: site is ginormous. If it moves really fast crawling might take too long to discover the link/sitemap, you really need a push mechanism so we built the indexing API for that
- Google shopping uses the same Googlebot as I understand, it looks like shopping changes are picked up much faster than organic search. You made announcements about changes coming to shopping and merging but we haven’t seen it rolled out – can we aspire to see that happen in organic search as well? Answer: we are still working on it. In an ideal world we wouldn’t ask you to submit it 2x, thats why we like the merchant center feed which is different than in a crawl model because it’s a feed. It would be good to use the feed for both organic and paid but we need to keep it clean to make sure paid data does not influence the organic pipeline
- Last Notes re: inaccurate info in rich snippets – I chatted with one of the PMs about how pricing queries can sometimes elevate incorrect or outdated information in rich snippets and it can create a lot of headaches for the in-house SEO. It was particularly frustrating because complaining about the result in the SERP seemed to be the only way to give feedback. He said that’s because the rich snippet and organic results are based off two different processes. Sometimes this creates results that do not meet expectations (my example was a company I worked with did not rank for (Brand + fees) but another site did that was out of date. His response was basically the rich snippet was not optimizing for something as fresh as my data and this is an unfortunate caveat that can happen but it should be getting better (it was an old example and I checked and this isn’t an issue anymore happily) 🙂
Food and Friends
It’s not a Google party without talking a little bit about the food and good friends. Of which Google delivered on both! For breakfast alone there was a donut wall, chia parfaits, a kefir yogurt bar and cheese and bacon croissants.



I even ran in to an old friend – Ryland! We were old coworkers in LA and he moved on to Yahoo where he drove SEO/ASO and is now driving SEO at Hulu. You can follow him at @rybacorn.
How do I learn about these events in the future?
I would honestly recommend getting started on Twitter. I know I know, why do SEOs like these 2nd rate social media platforms? I don’t know. But we do. But Twitter is absolutely one of the BEST ways to stay in touch with the SEO community and keep a pulse on SEO news. Follow Google, John Mu and any of the following to stay up to date on what’s new and what you should know:
- @johnmu – John Mueller is a favorite in the SEO community, not only for his humor but also his generosity, faith and support in the SEO community. He’s the long standing Webmaster trends analyst at Google
- @googlewmc – the official handle for Google Webmasters
- @methode – Gary Illyes – another key liaison between Google < > SEOs
- @searchliason – Danny Sullivan’s official tweets sharing “insights on how Google works”


11 Comments
Borislav Arapchev
Jackie, tons of amazing knowledge, thank you for your efforts and time!!
I guess you are so excited about the event.
Now lets read all of it 🙂
Kumar
Thanks for the fantastic write up ! Helps a lot of us who could not join the Google event. Hope you capture other days info too.
Cris Hazzard
Thank you so much for putting this together and sharing, really helpful and greatly appreciated.
GreenGoldStore
Hi Jackie
Thanks for sharing most important information on google webmaster conference at mountain view
Elizabeth
Thank you very much for this detailed recap of the event!
I hope you will continue posting here. I enjoy reading the posts.
E
Geo
¡Muchas gracias por compartir! 👍
FCE
A lot of curious technical issues were covered.
Sandra
Thank you so much for sharing! Very insightful and helpful.
obat penumbuh kumis ampuh
Nice post. I learn something new and challenging on websites I stumbleupon on a daily basis.
It’s always useful to read through articles from other writers and practice a little something from their web sites.
LeeGlass
I’ve learn some excellent stuff here. Certainly value bookmarking for revisiting. I surprise how a lot effort you put to create the sort of wonderful informative website.|
Vishal
fantastic post. glanced through it and have bookmarked to read later… great stuff !