An overview of ML development platforms
This article is the 1st in a series dedicated to Machine Learning platforms. It was supported by Digital Catapult and PAPIs.
Model development platforms greatly reduce the time and cost of creating ML models, for organizations of all levels of ML maturity. These platforms can be ready-made or custom-built, based on open-source or commercial software. Some of them also act as model deployment platforms, and in a few instances as model lifecycle management platforms, but their core is to run model training pipelines.
Depending on the model development platform, training pipelines can be more or less customizable and they can be run on your own machine or on cloud infrastructure. We can group ML development platforms into the following types:
- Semi-specialized platforms (e.g. for text or image inputs)
- High-level platforms as a service (mostly for tabular data)
- Self-hosted studios
- Cloud Machine Learning IDEs
This list of platform types is ordered by increasing level of flexibility — but note that this is at the cost of increased time for model development, configuration, and maintenance. Cloud ML IDEs are the most flexible and can be used with any type of data. However, most of the high-level platforms and studios only deal with tabular data. There are hundreds of ML platforms out there, so instead of trying to reference all of them, we'll present a variety of platforms for each type. Let's dive in!
Semi-specialized platforms: Language and Vision
Language platforms allow their users to train custom text models from their own data. Inputs would be text in a given language. For Vision platforms, inputs would be images or video. For both Language and Vision platforms, outputs would be labels that identify "concepts". These could "proprietary" concepts if you wish (for instance, references that are internal to our organization, such as project names or team names). You would provide your own training data to the platform (inputs and outputs), which would automatically create your own ML model. Note that the model training process may not be customizable, but at least you would be able to create working models fast.
Some example Vision platforms: Clarifai, Amazon Rekognition, and Google AutoML Vision. We show below how a model can be created in 2 API calls with Clarifai: one to send training data, and one to actually create the model.
$ curl https://api.clarifai.com/v2/inputs
-H "Authorization: Key YOUR_API_KEY"
-H "Content-Type: application/json"
-d '{ "inputs": [
{ "data": {"image": {"base64": "'"$(base64 /home/user/object1.jpeg)"'"},
"concepts": [ {"id": "defect", "value": true} ] }
] }'
$ curl https://api.clarifai.com/v2/models
-H "Authorization: Key YOUR_API_KEY"
-H "Content-Type: application/json"
-d '{"model": {
"name": "defect_detector",
"output_info": {
"data": {"concepts": [{"id": "defect"}]},
"output_config": {
"concepts_mutually_exclusive": true,
"closed_environment": false }}}}'
You would then be able to review your model and evaluate its performance.

Model evaluation and threshold adjustment in the Clarifai Portal
Some example Language platforms: Amazon Comprehend, Google AutoML Natural Language, and MonkeyLearn. Lateral is another interesting one, which includes a tag suggestion API (based on existing text documents and tags) and a recommendation API that recommends similar documents to a given text document. This uses a hybrid approach, where relevance is determined based on text content and user behavior.
Note that some of these platforms also offer data annotation services, to help create proprietary models (for instance, Google has a crowdsourced Data Labeling Service). If the platform you choose does not have such a service, there are dedicated data annotation platforms such as Figure Eight.
High-level platforms as a service
Platforms as a service are among the easiest to use, as there’s nothing to install and no need to worry about infrastructure. High-level features include:
- Automatic detection of the type of problem (for example, classification or regression)
- Automatic preparation of data (for example, encoding of categorical variable, normalization, feature selection and so on).
- Automation configuration of the learning algorithm (AutoML with meta-learning and smart search of hyper-parameters)
These platforms are particularly useful for those with less knowledge of ML algorithms, and they can be accessible to domain experts or software developers. Arguably, they are also useful for data scientists, as they allow for faster experimentation and fewer errors. This, in turn, allows focusing on everything that takes place before and after learning from data — which is what matters most in practice: gathering ML-ready data, evaluating predictions, and using them in software.
BigML
BigML is a platform that provides a variety of built-in algorithms for classification and regression (Decision Trees, Random Forests, Boosted Trees, Neural Networks, Linear and Logistic Regression) that supports numerical features and categorical features, as well as text features. It also gives access to unsupervised learning algorithms (clustering with K-means and G-means, anomaly detection with Isolation Forests, PCA, topic modeling) and time series forecasting (Exponential Smoothing). Its “OptiML” functionality implements AutoML techniques that find the best model for a given training set, validation/test set, and performance metric, in a given time budget. Its “Fusions” functionality creates model ensembles.

Inspecting a neural network created automatically by BigML, with an interactive partial dependence plot
The BigML API allows users to query predictions and trigger model training at scale, on the BigML cloud infrastructure. Let’s assume that BIGML_AUTH is an environment variable that contains the BigML username and API key. Here is how the API would be called to use OptiML for a given training and test datasets (identified by their ids), in a way that maximizes the Area Under the receiver operating characteristic (ROC) curve (AUC):
$ curl https://bigml.io/optiml?$BIGML_AUTH -d '{"dataset": "<training_dataset_id>", "test_dataset": "<test_dataset_id>", "metric": "area_under_roc_curve", "max_training_time": 3600 }'
The request is asynchronous and will return an OptiML id. After one hour (3600 seconds), the API can be hit to get information about the OptiML object created, in particular the summary which contains the ID of the best model that was found for the dataset. Predictions can then be requested from this model:
$ MODEL_ID = curl https://bigml.io/optiml/<optiml_id>?$BIGML_AUTH | jq -r ".optiml.summary.model.best"
$ curl https://bigml.io/predict?$BIGML_AUTH -d '{"model": "'"$MODEL_ID"'", "input_data": {"text": "I will never stay in this hotel again"}}'
BigML is probably the easiest platform to use among those presented in this section, but also the least flexible. ML practitioners will find missing functionalities, such as the ability to plot learning curves and to use a custom performance metric. However, BigML allows users to execute scripts on their platform in a language they created and called WhizzML, which is a high-level programming language specific to machine learning. This extends the functionality of the platform. It is also one of the most closed platforms here, as it does not play well with open source, so is limited in the format in which models can be exported, it is not possible to export modeling scripts — however, it is possible to see which algorithm and parameters were used to create a model.
Google products
Google AutoML Tables is a beta product which bears similarities to BigML, but is not yet intended for usage in critical applications. Its UI is simpler, and the product seems more targeted at developers than domain experts. Google Cloud Inference API focuses on time series prediction. It is an alpha product that doesn’t include a UI, but is more geared towards deployment in production.
Microsoft Azure ML
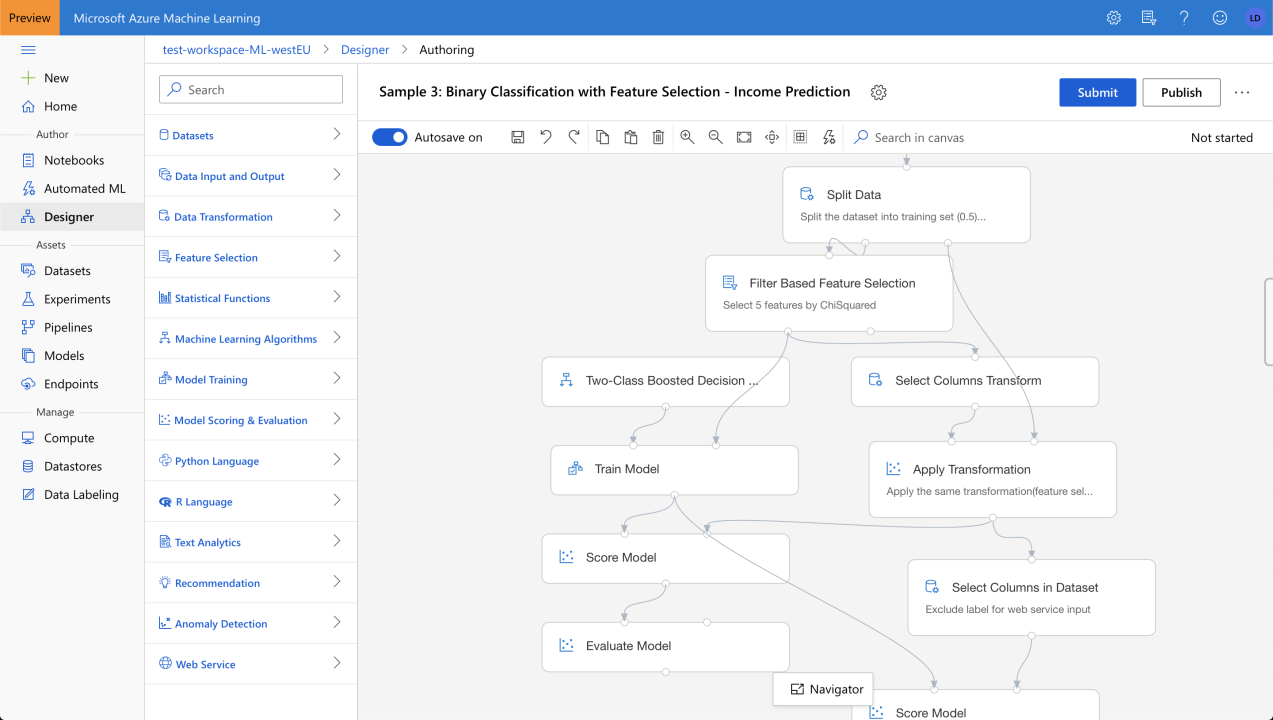
Microsoft Azure ML is an MLaaS platform offering a Studio with 2 model authoring environments: Automated ML, and Designer (previously called “interactive canvas”). The platform can also turn models into prediction APIs that scale automatically. The Designer allows users to view and visually edit model training pipelines, i.e. sequence of operations that take data in, prepare it, and apply ML algorithms to produce (and evaluate) predictive models. The Designer makes it easier to understand pipelines, but also to create them, by avoiding potential errors that are caught by the interface (for example, missing inputs to the data operations, or forbidden connections).

Microsoft Azure ML’s Designer
Lobe
Lobe is a service that Microsoft acquired in 2018, which also provides an interactive canvas and AutoML functionality, but also allows users to deal with image features. It provides an easy to use environment to automatically build neural network models, via a visual interface. Models are made of building blocks that can be fully controlled (Lobe is built on top of TensorFlow and Keras); some building blocks are pre-trained, which allows for transfer learning. Training can be monitored with real-time, interactive charts. Trained models can be made available via the Lobe Developer API, or exported to Core ML and TensorFlow files to run on iOS and Android devices.

Self-hosted studios
Several other studios offer a Designer, under different names — DataRobot calls it “Blueprint”, Rapidminer and Dataiku call it “Workflow” — and AutoML functionality. The ML development platforms mentioned here are seen as as lower-level than the previous ones, since they are not provided “as a service” and need to be installed and hosted on our own (cluster of) machines. However, they have interesting capabilities that were not found in the MLaaS offerings.
One common aspect that these platforms share is that they are based on standard open-source ML libraries, and allow users to use custom libraries and custom code. They let users export ML workflows/pipelines as Python scripts, and to export trained models to various open formats which avoids lock-in. Note that some of the vendors mentioned also provide separate deployment and model serving solutions.
Dataiku
Dataiku’s Data Science Studio (DSS) presents the following advantages:
- Connectors to many types of databases. Data sources can be changed from a CSV file to a Hadoop File System (HDFS) URI for instance, without having to change the rest of our ML pipeline
- Visual data wrangling, feature engineering, and feature enrichment, to improve data and help prepare it before usage in learning algorithms
- Different ML back-ends providing built-in algorithms. The back-end can be changed from scikit-learn to Spark MLlib for instance, without having to change the rest of the ML pipeline
- Built-in clustering and anomaly detection algorithms

Comparing MLlib models’ performance in Dataiku’s Data Science Studio
DataRobot
DataRobot has the following advantages:
- Automatic feature engineering
- Model inspection features and visualizations of prediction explanations
- Advanced time series forecasting: several built-in algorithms (ARIMA, Facebook Prophet, Gradient Boosting), backtesting evaluation method, automatic detection of stationarity, seasonality, and time-series feature engineering.

Prediction explanations in DataRobot
H2O
H2O’s Driverless AI is a similar product to DataRobot. Both have a Python API. Below is a call to the start_experiment_sync method of H2O’s Python API, which is similar in spirit to the OptiML method of BigML’s HTTP API:
params = h2oai.get_experiment_tuning_suggestion( dataset_key=train.key, target_col=target, is_classification=True, is_time_series=False, config_overrides=None) experiment = h2oai.start_experiment_sync( dataset_key=train.key, testset_key=test.key, target_col=target, is_classification=True, scorer='AUC', accuracy=params['accuracy'], time=params['time'], interpretability=params['interpretability'], enable_gpus=True, seed=1234, # for reproducibility cols_to_drop=['ID'])
Cloud machine learning IDEs
Our last type of model development platforms can be thought of as integrated development environments (IDE) for machine learning, hosted on the cloud. The platforms do not offer the high-level functionality of the ML Studios previously presented, but they benefit from cloud computing. It is common practice among machine and deep learning practitioners to use powerful, GPU-equipped virtual machines (VMs), provided by cloud platforms, for their experiments. These cloud VMs have been available before ML-specific cloud platforms were created. The platforms make it faster to run experiments, and easy to do 24/7 if desired. The platforms also make it possible to scale experiments with CPUs with many cores, powerful GPUs with a lot of RAM, and clusters that are already configured (for example, for distributed learning, tuning hyper-parameters in parallel, and using deep neural networks). Users only pay for what they use; there are no upfront costs to acquire costly hardware.
The new ML-specific cloud platforms give access to Jupyter Lab environments, as web-based IDEs, on preconfigured infrastructure. They provision cloud VMs with all the common open source ML libraries. TensorBoard web servers are usually included, for monitoring the progress of TensorFlow-based experiments. Cloud ML IDEs aim at making VMs available faster than other cloud services (typically from several minutes to seconds), and at making it more convenient to persist work done on these (short-lived) VMs.
Floyd
Floyd is a great platform to start with, as it is less complex to use than competitors, but still provides a few different options to run ML experiments. It gives access to two types of CPUs and two types of GPUs, to choose from depending on our needs. There are two different ways in which experiments can be run:
- Workspace, which is an IDE based on Jupyter Lab, for interactive experimentation. It also gives access to TensorBoard, and to a similar feature called Metrics, that can be used with any ML library (not necessarily TensorFlow) to monitor the progress of model training
- Jobs, for running longer experiments as scripts. Jobs are started from a command-line interface (CLI) tool installed on our own machine, in the same way as executing a script locally, but they are run on the Floyd platform. The CLI also allows users to tag jobs and to download outputs. The ability to browse the history of jobs, to filter with tags, and to see result summaries in the history, fulfills the role of an experiment tracker.
Another useful feature is the ability to store large datasets on the cloud platform and to share with the whole team, so there is no need to download the datasets locally and to keep them in sync. The Floyd infrastructure is built on top of Amazon’s North American public cloud, but Floyd can also be installed on private clouds and on-premise, which is one way it differentiates itself from Google and Amazon products. For European companies, Faculty.ai provides an alternative based in the UK.

Google AI Platform Notebooks
Google AI Platform Notebooks is similar to Floyd Workspace. It uses the platform’s Deep Learning VM Image and its Cloud TPUs (tensor processing unit). It has built-in Git support and integrates with Google AI Hub, a product that helps discovery of what others have built within the organisation (such as notebooks, pipelines and models) that one should check before starting a new development. Since Notebooks is a Google Cloud product, it gives access to pre-configured/pre-installed Google Cloud Platform libraries such as Dataflow and Dataproc for data wrangling. GPUs can be added to or removed from the cloud VMs used by the platform, whereas Floyd is limited to 1 GPU per VM.
AWS SageMaker
SageMaker is Amazon’s ML platform, which offers a similar development environment and facilitates the use of cluster computing for distributed model training and distributed hyper-parameter tuning experiments. SageMaker allows users to define model training jobs via its Python API and a dictionary data structure where the datasets are defined to use for training and validation, hyper-parameter values for the training algorithm, and resources for running the job.
training_params = \
{
"AlgorithmSpecification": {
"TrainingImage": image, # specify the training docker image
"TrainingInputMode": "File"
},
"RoleArn": role,
"OutputDataConfig": {
"S3OutputPath": 's3://{}/{}/output'.format(bucket)
},
"ResourceConfig": {
"InstanceCount": 1,
"InstanceType": "ml.p3.2xlarge",
"VolumeSizeInGB": 50
},
"TrainingJobName": "model_a",
"HyperParameters": {
"image_shape": "3,224,224",
"num_layers": "18",
"num_training_samples": "15420",
"num_classes": "257",
"mini_batch_size": "128",
"epochs": "2",
"learning_rate": "0.2",
"use_pretrained_model": "1"
},
"StoppingCondition": {
"MaxRuntimeInSeconds": 360000
},
"InputDataConfig": [
{
"ChannelName": "train",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": 's3://{}/train/'.format(bucket),
"S3DataDistributionType": "FullyReplicated"
}
},
"ContentType": "application/x-recordio",
"CompressionType": "None"
},
{
"ChannelName": "validation",
"DataSource": {
"S3DataSource": {
"S3DataType": "S3Prefix",
"S3Uri": 's3://{}/validation/'.format(bucket),
"S3DataDistributionType": "FullyReplicated"
}
},
"ContentType": "application/x-recordio",
"CompressionType": "None"
}
]
}
sagemaker.create_training_job(**training_params)
The platform also provides project templates for various ML tasks, including advanced ones such as sequence-to-sequence learning, and reinforcement learning.
Databricks
Databricks Unified Analytics Platform allows users to access cluster computing on Amazon or Microsoft’s cloud platforms. Databricks maintains Apache Spark, a leading open-source cluster-computing framework. The platform also gives access to Databricks’ other open-source framework, MLflow, which has an experiment tracking component. MLflow is designed to scale to large data sets, large output files (for example, models), and large numbers of experiments. It supports launching multiple runs in parallel (for example, for hyperparameter tuning) and executing individual runs on Spark. It can take input from, and write output to, distributed storage systems.
Coming up next: more types of ML platforms, and limitations
I hope this article convinced you of the power of model development platforms, and that you have an idea of which type might be the best fit for you.
In the next articles, I'll introduce other types of ML platforms (deployment, vertical, pre-trained), I'll give tips to help you choose the best ones for your organization, and I'll discuss what's missing from these platforms in order to build real-world ML systems. Follow me on LinkedIn to get notified!
- Head over now to the 2nd article in this series on ML platforms: The 9 components in a real-world Machine Learning system.
- Go straight to the 3rd article: An introduction to ML deployment platforms.
Making it easier to create value with ML systems
3yHere's the follow-up article on **deployment** platforms: https://www.linkedin.com/pulse/introduction-ml-deployment-platforms-louis-dorard Enjoy!
Chief of staff of Communauté d'agglomération de Blois.
4yVery interesting overview Louis Dorard ; thanks for sharing.
Strategy & Leadership - Software & AI products/projects/teams | AI Expert @ BPI France
4yGreat overview of the ML toolsuite ! Thanks Louis Dorard
VP Data Science at 2U & Founder of MLinProduction.com
4yNice article, Louis Dorard. I've recently released a blog post on how SageMaker can be used to solve common ML workflows such as experiment tracking, model deployment, and monitoring. It might be useful to your audience. https://mlinproduction.com/5-challenges-to-ml-in-production-solve-them-with-aws-sagemaker/
Non Executive Director - Board Director - Chair Audit & Risk - Early Stage VC/PE - Faculty @ Northeastern University
4yGreat work, thanks for sharing Louis Dorard