Millions of small websites, app backends, and various high-profile services are offline or experiencing severe issues because of a mysterious problem that hit Amazon's S3 (Simple Storage Service) a few hours ago.
Current reports indicate that a large number of services have been affected and are completely offline. Many other services and websites are also loading very slowly, while others services report that multimedia content doesn't load at all, mainly because it was hosted on S3.
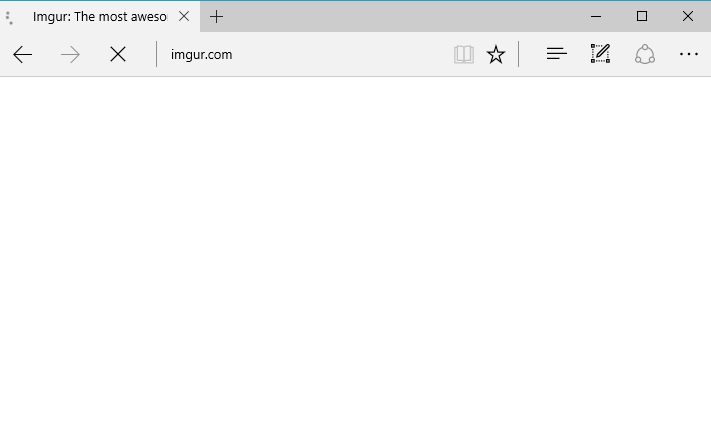
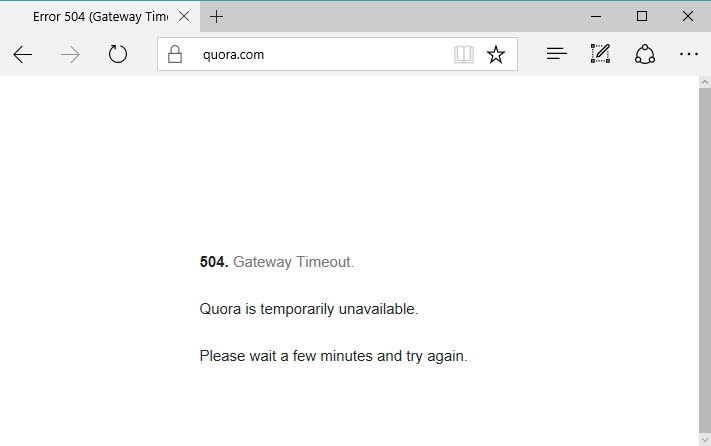
The list of affected AWS customers includes many of Adobe's apps and services, Docker, Giphy, Grammarly, Hacker News, IFTTT, Imgur, Mailchimp, Medium, Quora, Signal, Slack, Trello, Twilio, Twitch, and countless of smaller apps and websites.
We are experiencing an outage from our service provider, @awscloud - please be patient as we await their resolution.
— MyFootballNow.com (@MyFootballNow) February 28, 2017
 |
 |
 |
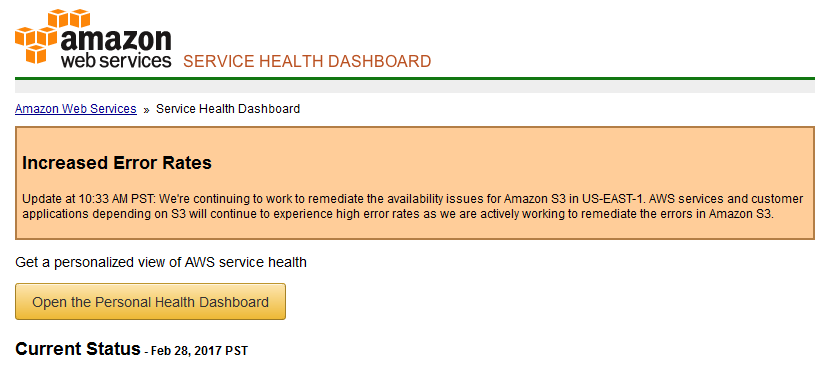
Many webmasters are currently reporting an "{ "errorCode" : "InternalError" }" message. According to Amazon's AWS status page, the issue first appeared two hours ago, around 10:33 AM PST, and has escalated ever since, hitting more services each passing minute.
"We're continuing to work to remediate the availability issues for Amazon S3 in US-EAST-1," the AWS page reads. "AWS services and customer applications depending on S3 will continue to experience high error rates as we are actively working to remediate the errors in Amazon S3."
Even if Amazon says that only one region is down, the entire situation is very strange because AWS was built for these situations and other AWS regions should have been able to cover for the downed region.
Don't forget about everyone's favorite passtime during an Internet outage, which is going on Twitter and reading tweets from angry server owners. Here's a link to the #AWS hashtag.
Developing. Story will be updated as details become available.
Update at 11:35 AM PST: Amazon says it repaired its status dashboard, which incorrectly showed that most AWS nodes were fine. Now, the AWS status board shows that the high error rates from the US-EAST-1 region has impacted many other nodes in North America, which explains why so many online services are affected. Full update below.
Amazon S3 according to the #AWS status page. pic.twitter.com/WpMAyHs0nY
— David C. Campbell (@DCCampbell) February 28, 2017
Update at 1:12 PM PST: AWS S3 is starting to slowly recover. Errors are still impacting some customers, but Amazon says it's only a matter of time until service is fully restored. Shawn Moore, CTO at Solodev, estimates that nearly 20% of the Internet was impacted by Amazon's outage.


Comments
JohnC_21 - 7 years ago
Ain't the cloud wonderful. :-P