Papers with Code Newsletter #4
👋🏻 Welcome to the 4th issue of the Papers with Code newsletter. In this edition, we cover:
- the latest progress in self-attention vision models 🏞,
- an efficient CapsNet architecture based on self-attention routing 👁,
- a unified framework for vision-and-language learning 🔮,
- Dataset feature release! We highlight some new datasets added to Papers with Code 🗂,
- ...and much more!
Trending Papers with Code 📄
Recent Progress in Self-Attention Vision Models [CV]
Self-attention continues to be adopted to build deep learning architectures that address computer vision problems like instance segmentation and object detection. One recent example is Vision Transformer (ViT) proposed by Dosovitskiy et al. Despite being promising for vision tasks, these large models can show computational inefficiencies and inferior performance (compared to established vision architectures). This leaves room for improvements. Here are highlights on some of the recent progress in self-attention visual recognition models:
Bottleneck Transformers
The memory and computation for self-attention scale quadratically with spatial dimensions. This is important to consider when image sizes are larger such as is the case in instance segmentation and object detection. This causes training and inference overheads. To address this issue, Srinivas et al. (2021) propose a hybrid vision model, BotNet, that achieves strong performance while being 2.33x faster in compute time than EfficientNet models on TPU-v3 hardware. BotNet presents a simple hybrid design replacing spatial convolutions with global self-attention in the last three bottleneck blocks of a ResNet. In essence, BotNet relies on both convolutions and self-attention to achieve strong performance on the COCO validation set and ImageNet benchmark.
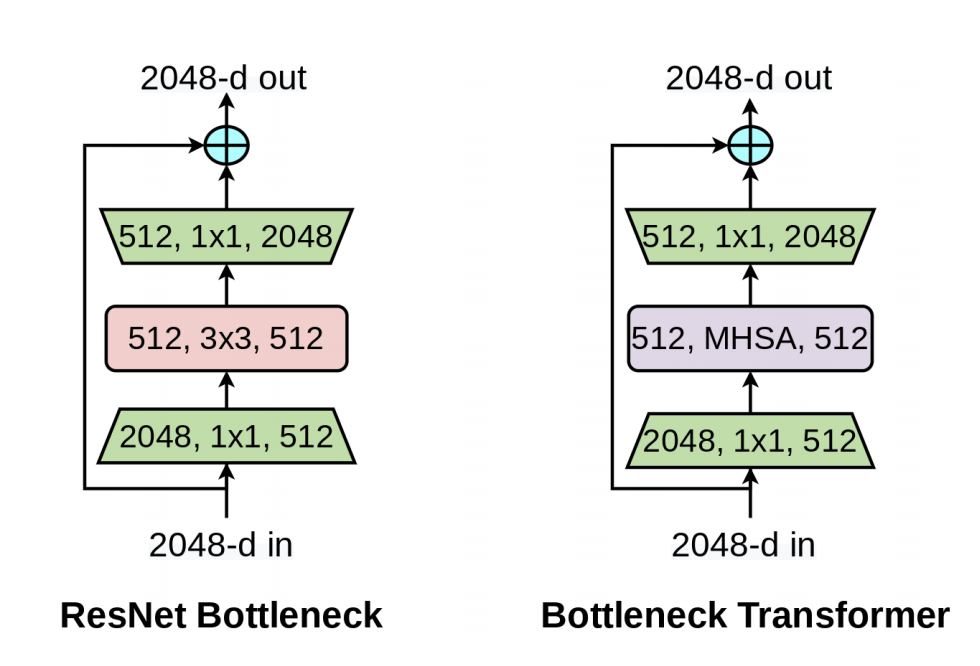
Bottleneck Transformer (right) replaces 3 X 3 convolutional layer with Multi-Head Self Attention (MHSA). (Figure source: Srinivas et al. (2021))
Tokens-to-Tokens ViT
Yuan et al. (2021) identifies that current Transformer vision models are unable to model local structure like edges and lines. They report that these models may also produce limited feature richness and are difficult to train for vision tasks. To model local structure more effectively, a tokenization module that recursively aggregates neighbouring tokens to one token is proposed. This allows the architecture to model local structure presented by surrounding tokens and reduce the length of tokens. The second contribution is a deep-narrow backbone architecture to improve feature richness and the overall performance of the vision transformer while significantly reducing parameter counts.

Overall architecture of the proposed T2T-ViT architecture. (Figure source: Yuan et al. (2021))
A Visual Self-Attention Taxonomy
Srinivas et al presented a taxonomy of deep learning architectures using self-attention for visual recognition. Below we've assembled links to these building blocks and architecture on Papers with Code, so you can see exactly how attention is implemented:
- SASA - 🔗 Ramachandran et al. (2019)
- LRNet - 🔗 Hu et al. (2019)
- SANet - 🔗 Zhao et al. (2020)
- Axial - 🔗 Ho et al. (2019)
- ViT - 🔗 Dosovitskiy et al. (2021)
- BotNet - 🔗 Srinivas et al. (2021)
- DETR - 🔗 Carion et al. (2020)
- VideoBERT - 🔗 Sun et al. (2019)
- ViLBERT - 🔗 Lu et al. (2019)
- Non-Local Net - 🔗 Wang et al. (2018)
- GCNet - 🔗 Cao et al. (2019)
- CCNet - 🔗 Huang et al. (2019)

Taxonomy of deep learning architectures using self-attention for visual recognition. (Figure source: Srinivas et al. (2021))
Capsule Network with Self-Attention Routing [CV]
CapsNet is an architecture proposed to efficiently encode feature affine transformations and increase model generalization for vision tasks. They have shown to be effective at vision tasks and aim to address the inefficiencies of previous state-of-the-art models for computer vision. In a recent development, Mazzia et al. propose a deep learning architecture based on CapsNet, called Efficient-CapsNet. This new method propose some architectural improvements targeted at producing more efficient models.
What's new: Efficient-CapsNet replaces the original routing algorithm by a non-iterative, self-attention routing algorithm to efficiently route a reduced number of capsules. Results show that the proposed model helps to encode robust and meaningful properties in the components of the output capsules. Efficient-CapsNet is an architecture with 160K parameters; it achieves state-of-the-art results on three different datasets with only 2% of the original CapsNet parameters.
 Efficient-CapsNet overall architecture. (Figure source: Mazzia et al. (2021))
Efficient-CapsNet overall architecture. (Figure source: Mazzia et al. (2021))
Unified Framework for Vision-and-Language Learning [DL]
Models for vision-and-language learning are designed with task-specific architectures and objectives for each task. Current vision-and-language transformer models for downstream tasks, like visual question answering, require designing task-specific, separately-parameterized architectures on top of the transformer encoder. These type of architectures don't consider the significant overlap in reasoning skills required by these tasks. To avoid the hassle of training different architectures for different pretraining and downstream tasks, Cho et al. propose a unified framework that learns different tasks in a single architecture.
What's new: The proposed unified framework learns different tasks in a single architecture by employing a multimodal conditional text generation approach. The model, which is trained using the same language modeling objective, learns to generate text labels conditioned on multimodal inputs. The proposed model achieves comparable results to recent state-of-the-art vision-and-language pre-trained methods. The method also involves less engineering efforts as compared to task-specific architectures and shows better generalization ability.

The proposed unified framework for vision-and-language tasks. (Figure source: Cho et al. (2021))
Trending Libraries and Datasets 🛠
Trending libraries/tools of the week
ZeRO-Offload - enables democratization of large model training. As an example, results demonstrate that it can train models with over 13 billion parameters on a single GPU without sacrificing computation efficiency or requiring model changes.
Trending with 4276 ★
PixelLib - is a Python library that allows easy implementation of object segmentation in real-world applications. It currently supports semantic segmentation and instance segmentation.
Trending with 274 ★
WeNet - is an open-source toolkit to efficiently deploy automatic speech recognition applications in several real-world scenarios.
Trending with 470 ★
FinRL - is a deep reinforcement library that provides tools to allow beginners to expose themselves to quantitative finance.
Trending with 1130 ★
Trending datasets of the week
ArtEmis - is a large dataset to better understand the interplay between visual content and its emotional effect, including explanations of the effect.
Trending with 139 ★
ToTTo - is an open-domain English table-to-text dataset with over 120,000 training examples that could be used as a benchmark for conditional text generation.
Trending with 230 ★
DAF:re - is a large-scale, crowd-sourced dataset for anime character recognition with close to 500,000 images spread across more than 3000 classes.
Trending with 33 ★
Community Highlights ✍️
- Thanks @adityac8 for adding the Darmstadt Noise Dataset which is useful for benchmarking denoising algorithms.
- Thanks @dbelli for adding several results to papers and adding the new Toulouse Road Network dataset.
- Thanks @mar for adding several datasets for fake news detection research (e.g., SVDC Fake News Dataset and FakeNewsAMT & Celebrity).
- Thanks @bastilam for adding the Cam2DEV dataset which is used for semantic segmentation research.
- Thanks @tienduang for many additions to benchmarks including results for a recent paper Learning Data Augmentation Strategies for Object Detection.
- Thanks @Eklavya for adding several datasets including FERET-Morphs and FRLL-Morphs.
Special thanks to users @dwromero, @Shareef, MChaabane, @ahundt, @mahdip72, ZhijianOu, @adityac8, @donovanOng, and the hundreds of contributors for their many contributions to Papers with Code methods, datasets, and benchmark results.
More from PWC 🗣
This week Papers with Code launched an index of over 3000 ML datasets. This is our first step to make research datasets more discoverable. With the new feature you can:
- browse datasets by task (e.g., Question Answering, Semantic Segmentation), modality (e.g., Videos, Text, Environment) or language (e.g., English, Chinese, Spanish),
- keep track of the newest datasets in your area of interests (e.g., Visual Question Answering, Autonomous Driving),
- browse benchmarks evaluating on a particular dataset,
- discover similar datasets,
- and view usage over time in open-access research papers.
We focus on datasets introduced in ML papers. This is an open resource so anyone is free to edit and add new datasets. We welcome suggestions, comments and feedback.
ICYMI, see previous issues of the newsletter here. We would be happy to hear your thoughts, feedback, and suggestions on the newsletter. Please reply to elvis@paperswithcode.com.
