

A lot of the time I see and speak to people asking about DR solutions when what they really want is HA with a few backups so I wanted to use a blog article to go through some of the technical terms used in conjunction with DR.
When people say “I want DR”, I’ll ask them about the sort of disasters they are looking to protect against and most of the time the response is “I want to keep working if my hypervisor crashes”.
A hypervisor crash is not a disaster. It may not be good for the company if everything is on one host but it’s not a disaster because everything else is working. You’ve still got your networking, your datacentre, your users still have their desktop machines and so on. It has to be expected that sooner or later a hypervisor will crash, possibly due to a bug in the hypervisor code or due to a hardware problem or similar but sooner or later, that hypervisor is going to go down. Let’s not forget that there also needs to be planned downtime for hardware upgrades, software patching and so on.
What they are actually asking for here is HA, the ability to either manually or automatically fail over from one host to another in the event that a host goes down and it’s a reasonable expectation, after all, a hypervisor crash can and does happen. Sometimes you might want to shut down a hypervisor for patching or other work and one of the great advantages of virtualization is the ability to do exactly that.
The problem though is that high availability in VMware and Hyper-V is not very well understood. People seem to have the impression that HA means an instant fail over but it doesn’t work that way.
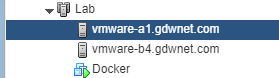
As you can see above, I’ve setup a VMware HA lab, the VM’s are on shared storage. If a host fails….
Then the failover takes several minutes to kick in. The reason for this is that VMware does some checks to ensure that that, yes, the host really has crashed. Once it accepts that the host is down, VMWare HA will kick in and take ownership of the VM’s. At this point, the VM’s have essentially crashed and will need to be restarted. This can be a somewhat hit and miss affair as a lot of the time Linux servers will get as far as a FSCK screen.
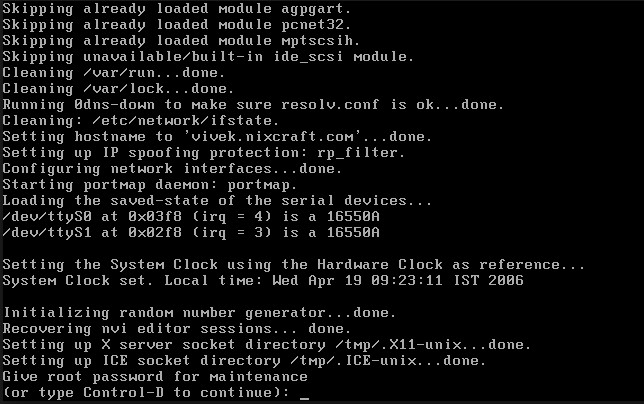
The way that HA failover works in VMWare is exactly the same way that clustering works in both Windows and on Hyper-V. HA at the hypervisor level cannot simply fail over instantly because that has the risk that a failover event could be triggered needlessly.
As you can see, HA at the VMware level isn’t very seamless. It works but there is downtime, there might be issues when a VM reboots and it requires shared storage which itself is a single point of failure.
So, what other options do we have? Well, there is Fault tolerance in VMware but this requires an enterprise license.
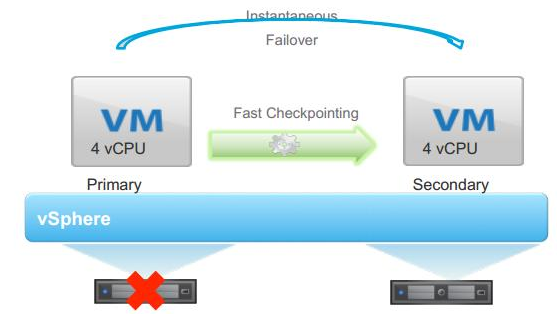
However, even with fault tolerance, if the VM crashes for some reason, so will it’s fault tolerant copy. Fault tolerance only works at the hypervisor level. It doesn’t care what is going on at the OS level, if the software crashes, well tough. Likewise, if someone does something they shouldn’t such as stop a service then the fault tolerant copy will do the same.
So, what can be done with applications that need a near continuous level of uptime?
Fortunately, these days a lot of applications are getting quite good at having a level of HA built into them.
For example, Active Directory is HA right out of the box. If AD is setup properly and if there are at least two DC’s on different hardware than a failure of a DC, even if it’s the FSMO role holder should go largely unnoticed.
Similarly, with Exchange and SQL, there is the option for a level of HA which is built right into the application itself. SQL Always On requires databases to be in full recovery mode which can be expensive in terms of transaction logs especially on servers with highly changing rates of data.
With file servers there is DFS, yes, it does require double the disk space but, if set up correctly, it does provide an ideal HA environment for file servers.
For applications that don’t have some level of HA built it then clustering the application (if the application supports it, quite a few don’t) is an option. However, in quite a few cases it may be that failover/recovery requires a level of manual intervention to get things back online.
None of this negates the need for DR of course, The 3-2-1 rule (3 copies of the data, on two different sets of media and at least one offsite) is still very much the rule to follow for backups. DR should still be tested because you don’t want to be testing your DR process when a disaster hits.
If you have a DR site then tools like VMWare replication and Veeam replication are excellent for getting data out of the primary Datacentre and into the secondary datacentre but, wherever possible, it is always best to have fault tolerance built into the application layer as this way you don’t have to rely on shared storage, application stability, heartbeat networks or anything like that as the application has what it needs to keep everything in sync. This doesn’t negate testing of course but this is something that can be built into a maintenance plan as it becomes a lot easier to take down an application node such as an Exchange server in the DAG over taking down an entire Hyper-V or ESXi host.
