


Keeping Tests Valuable: Using Branching Coverage to Improve Software Quality
Branch coverage provides valuable insight into areas of your code that require the most attention and testing.


There are topics about tests that can sometimes go unnoticed, but when we analyze them carefully and dive into the studies to understand how much value we can extract from a certain topic, we are amazed. In this article, we will talk about branch in code coverage. It may seem like a simple topic, but I assure you that we can explore a lot and extract maximum value from our tests with this coverage metric. Let's start by better understanding how this metric is generated.
How does branch coverage work?
Branch coverage testing is a technique that aims to ensure that all different branches of source code are executed during testing. A branch is a conditional statement in code that redirects program execution along different paths. The branch coverage test is intended to ensure that both true and false branches are executed during tests, to increase software reliability and identify possible errors or failures. All developers who work with testing, usually come across this report generated all day long. The report for each class is very simple when we are talking about the calculation of branches that a code can have, let's see a simple example:
public class Phone
{
public bool isValid(string phone)
{
if (phone == null)
{
return false;
}
if (!phone.All(char.IsDigit))
{
return false;
}
if (phone.Length < 11)
{
return false;
}
if (phone.Length > 13)
{
return false;
}
return true;
}
}
This code above is quite simple but serves very well for didactic purposes. In this case, we will start with a test with a happy path:
public class PhoneTest
{
[Fact]
public void IsValid_ValidPhone_ReturnsTrue()
{
//Arrange
string phone = "11999999999";
var obj = new Phone();
//Act
var result = obj.isValid(phone);
//Assert
Assert.True(result);
}
}
Now see the image with the report of coverage by lines and also coverage by branch:
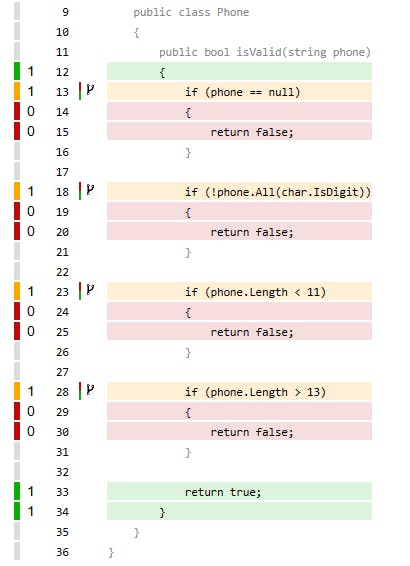
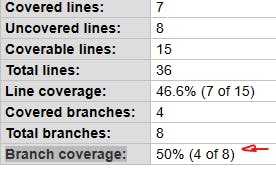
It is interesting to note in the generated report that there are still 4 missing branches that were not reached by the test. After all, we only tested the happy path. This report still provides more useful information, see the next image:
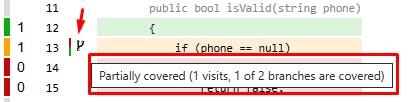
When you hover the mouse pointer over the icon in the image with an arrow, you see this information in the image above 👆, so we had a visit in this line and the conditional structure was partially covered. It seems simple, but it is important information that helps us a lot daily.
Now going forward, we can ask ourselves: Ok, we have 4 IF blocks, but why do we have 8 branches in total as the report points out?
The isValid() method has 8 branch paths because there are four IF conditions in the code, each with two possible paths. Let's look at each of these conditions:
The first condition checks if the phone is null. This condition has two possible paths: one where the phone is null and the method returns false and another where the phone is not null and the method proceeds to the next condition.
The second condition checks whether the phone contains only digits. This condition has two possible paths: one where the phone contains only digits and the method proceeds to the next condition, and one where the phone contains other characters and the method returns false.
The third condition checks whether the phone has less than 11 characters. If it is less, the method returns false. Has two possible paths: one where the phone has less than 11 characters and the method returns false and another where the phone has at least 11 characters and the method proceeds to the next condition.
The last condition checks whether the phone has more than 13 characters. Again, this condition has two possible paths: one where the phone has more than 13 characters and the method returns false, and another where the phone has at most 13 characters and the method finally returns true.
Ok so we have seen how this metric is generated, now let's quickly understand the calculation. We can do this manual calculation with the following formula:
(Branches traversed / Total branches) * 100
In the case of the Phone class, the code has 8 ramifications in total and the automated tests go through 4 of them, the basic ramification coverage will be 50%.
Everything we have seen shows that branch coverage is a valuable resource that can be used to help us in many ways, let's understand how we can use this tool daily to improve the quality of our code and also of our tests.
Too many branches should raise an alert
When a code has many conditional statements, it can create a large number of possible execution paths, which can make it difficult to cover all possible deviations with test cases. By measuring branch coverage, we can get an indication of how many of these branches have been covered by tests. If the branch coverage is low, it may suggest that the code is very complex and that many possible execution paths have not been tested.
For example, if a function has many nested if/else statements or switch statements with many cases, it may create a complex control flow that is difficult to cover completely. By measuring branch coverage, we can identify which branches have not been executed and may need additional test cases to be written. Take a look at this example:
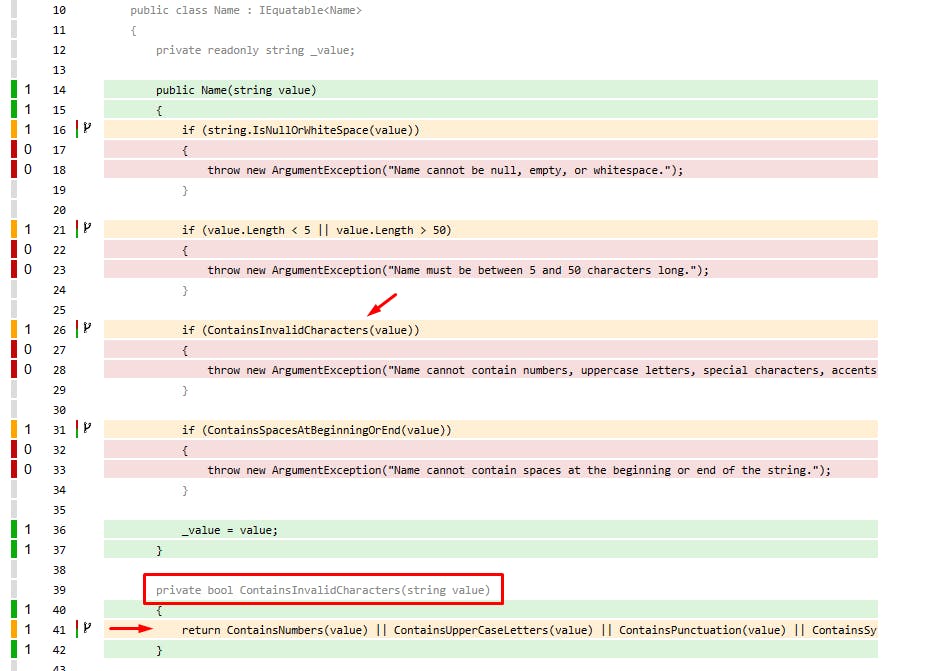
The ContainsInvalidCharacters() method has 8 branches with only 4 being covered.

This may not seem like a big problem, but we know that most software has rules and branches that perform much more important operations and affect millions of users. If the tests we write do not cover all the branches, this can be very dangerous, especially when the functionality is critical to the operation of the software. To avoid unexpected bugs that hide on the borders of conditionals and loops, it is essential to try to test all possible branch exits.

See that we have 22 branches present in the Name class. This class has no complex validations. But the point of this example is to show the importance of checking the level of complexity of the code and the number of branches that the final report shows. The larger the number of branches in a single method or class, the more complex it becomes to understand the flow from beginning to end. The larger the number of branches, the more difficult the code becomes to read and understand, which can make it difficult to identify possible problems or errors.
Developers should always be aware of the high number of branches in methods and classes. If a class has so many branches that it is difficult to read the code, these are probably the signs that the class needs to be refactored. It is also known that in some cases we cannot refactor the method and all its branches, but we can choose specific code snippets that can be allocated to new classes, thus reducing the number of branches and making the code easier to read.
Many tests written but few branches covered
I've seen this happen mostly in corporate applications with lots of business rules. Mainly due to the lack of criteria of developers who always try to allocate validations in the same UseCase (often UseCases that had no relation to the context). The scenario is similar to this one. A new feature is requested and the team meets and discusses how they will develop the functionality. They decide to allocate it to a UseCase that already has too many responsibilities. By doing this, the number of branches increases and the class becomes very large. When writing the tests, the developer notices several ramifications not covered in the report. But since he doesn't have time to test all the branches the code does, he just writes the test the happy way. This scenario is not hard to see in the corporate world. Usually, you will notice that in many projects there are classes with a lot of tests, but when generating the report, we see many branches without the proper tests. And what problems can this bring? I will list some of them:
Regression risk: If too few branches are covered by tests, there is a risk that future changes in the code will affect untested paths.
Low confidence: If the tests do not cover all the important ramifications, more time and effort may be needed to retest and debug the code.
Undiscovered defects: If the test only covers a few ramifications, it can result in low confidence in the quality of the software, as undiscovered defects can cause problems for end users and affect the overall quality of the software.
We should be concerned if we have many tests running and still many branches without coverage because a very large test suite demands refactorings and understanding all the rules of each class in addition to understanding the flow of each structure for, while, and conditional, if ever let's leave it for later, this will accumulate and prevent the healthy progress of the tests and the software itself. We certainly don't want that technical debt within our test suite.
Should we set a maximum number of branches per class?
In my opinion, there is no benefit in doing this. Because setting maximum numbers per class just encourage developers to think:
" Okay, I can get close to that or the limit, so instead of thinking of strategies to improve this class, split this method or create a new class, I'm just going to defer that responsibility to another time.
I'm not saying that all developers do this! In addition, some circumstances can lead the developer to act in this way, such as pressure and time. But don't you think that's what would happen to some? This thinking encourages them to get as close as possible to the maximum number allowed instead of thinking about how to reduce the number of branches in the algorithm. I'm not in favor of defining numbers, I like the idea of always encouraging the team through code reviews and also analyzing the generated reports, each developer should analyze how it would be possible to reach the lowest possible number for each context. Defining a number can only bring more complexity to the development process. We don't want that! We want developers to think about keeping the code simple and modular, to facilitate test writing and future maintenance. Below are some recommendations of what we can do to keep the branching level acceptable at all times:
Avoid excessive nesting: Excessive nesting can make the code difficult to read and understand. It is recommended to have no more than 3 levels of nesting.
Keep logic simple: Complex logic with many conditions and loops can make it difficult to write tests. It is recommended to keep logic simple and separate it into smaller functions/classes.
Use design patterns: Using design patterns can help keep code modular and simple to understand. Some common design patterns include the factory pattern, the adapter pattern, and the strategy pattern.
By following these steps and taking them seriously, you will notice a big difference in both the readability and maintainability of the code.
Testing is a creative activity that involves much more than simply running test cases. Software engineers must have critical thinking skills and creativity to create tests that really work. - Hundred Kaner
Can branch coverage help reduce development time?
In part yes, because when we worry about covering all the branches and creating tests with good practices, we have more assurance that all the inputs and outputs have been analyzed. Writing tests just to cover the happy path creates uncertainty about whether that functionality is behaving the way it should in the software:
Identifying problems earlier: With branching coverage, testers can identify problems and bugs in code earlier in the development process. This helps avoid the need to perform more complex and time-consuming fixes later in the development process.
Reducing testing time: It is possible to focus on testing the most critical areas of the code. This means that less time is spent testing less important areas, reducing the time required to perform testing.
Increasing testing efficiency: Branching coverage helps ensure that tests are targeted at the areas of the code that are most critical and susceptible to problems. This means that testing is more efficient and less time is spent testing less important areas of the code.
Improving code quality: By ensuring that all branches of the code are tested, branch coverage helps to identify problem areas and improve the quality of the code. This can help reduce code maintenance time and costs in the future.
It is important to point out that this can be applied to any project, but it also depends a lot on the current situation of the code base. These tips we saw will not magically solve the problems and increase the speed of delivery of the teams. These tips serve as an incentive for everyone on the team, as everyone needs to apply good practices when writing code and writing test cases.
Can branch coverage help improve the quality of features?
We can say that branch coverage is useful for this too. It won't be a lifesaver, but by using this part of the report to analyze important branches that are untested we can analyze and write quality tests for these parts and to some extent improve the testing of these features. We can make a quick analogy to explain this better.
Imagine an airport, there are various protocols, validations and rules to be followed, we know that security is high at airports. The number of branches not covered in the code would be like the number of security holes in the airport. If the agents don't check all the security holes, passengers can bypass security and bring dangerous objects with them. If they know that an airport path gives easy access to places that are essential to the operation of the airport, then it is essential to correct this, this path should be covered by checking and security steps only for people with legitimate access.

Similarly, if there is not proper coverage of branching in the code, important parts may go without proper testing and contain bugs and vulnerabilities that could affect the functionality or the entire system!
Therefore, just as security officers need to check every security breach at the airport, developers need to ensure that every part of the code is tested. We must not give bugs a chance in our software!
Branch coverage helps ensure that every possible path through your code is tested, improving the overall quality and reliability of your software.- Jeff Offutt.
Conclusion
Branch coverage provides a clear perspective of which areas of the code need more attention and testing. In conjunction with other techniques, programmers can ensure that the code is properly and thoroughly tested. However, it is important to remember that branching coverage alone does not guarantee the quality of the software, as this also depends on other factors such as the readability of the code, ease of maintenance, adherence to best practices, abstraction, and many other factors.
Ultimately, we can use this coverage metric to help us improve software quality. By putting a little bit of what we have seen into each day and giving more value to this metric and its numbers, we begin to better understand the level of complexity of a class, method, and the entire project, and this allows us to have a more detailed view of each component of our system.
I hope this post helped you, if you liked it, please share it with others! See you next post! 😉😄
References:
Why do developers hate code coverage? And why they should not hate it!
Books: