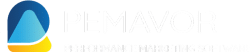

Get notified when a Python SEO audit job returned some issues and attach detailed information in a file to the Slack notification to make actions right away.
Many of you were curious to know how it could be integrated with Slack for seamless notifications and faster resolution of issues. So, without further ado, we delve into this topic.

How to set up your own automated SEO monitoring solution in Slack
With three example audit scripts:
- Add Settings in your Slack environment to make it possible to send notifications and file uploads
- Audit Job #1: “Sitemap Status Code Checker“
Report the number of cases with status codes different than 20x
Attach URL + Bad Status Code as File to the message - Audit Job #2: “Internal Link Checker”
Check all internal links found on the website – report the number of cases with bad status code
Attach file for bad cases with URL where the link was found, the link URL, the link status code and the link anchor text - Audit Job #3: “Missing Meta Description Checker”
Check for missing meta description on all URLs – report the number of cases
Attach URLs with missing meta description as file
We added two more SEO audit scripts into the running example. The message we want to deliver is that you can have a lot of jobs like that – this is a blueprint for building your own SEO monitoring solution. Be creative. Maybe you can set up some monitoring tasks on your competitor websites to monitor exactly what they are doing.
Setting up your monitoring App in Slack
First of all, you need first a running Slack environment of course. Slack has a free plan that should be more than fine for most.
- If you have a running Slack Workspace go to this link and create a new app.
- Click on “Create new app”.
- Enter your app name, e.g. SEO Monitoring, and select your Slack workspace.
- After creating the new app, you have to add some features for sending notifications and files to Slack out of your Python script. Go to “OAuth & Permissions”.
- Under “Bot Token Scopes” please add the following OAuth Scopes:
files:write
channels:join
chat:write - Click “install to the workspace” and you will see an OAuth Access Token: This is what you need to copy and paste in your Python script.
- Nearly done with the Slack part – now just choose a channel where you want to send messages to. Use the “Add Apps” menu item and search for your SEO monitoring app.
3 basic SEO audits written in Python
As already mentioned, this is only a blueprint on how to set up your own audit solution. Add as many check routines as you want. Just change the sitemap URL and add your Slack OAuth Access Token, and you are ready. Here is the code:
# Pemavor.com SEO Monitoring with Slack Notifications
# Author: Stefan Neefischer
import requests
from urllib.request import urlparse, urljoin
from bs4 import BeautifulSoup
import advertools as adv
import sys
import json
import time
import pandas as pd
import warnings
warnings.filterwarnings("ignore")
def slack_notification_message(slack_token,slack_channel,message):
data = {
'token': slack_token,
'channel': slack_channel,
'text': message
}
url_chat='https://slack.com/api/chat.postMessage'
response = requests.post(url=url_chat,data=data)
def slack_notification_file(slack_token,slack_channel,filename,filetype):
# link to files.upload method
url = "https://slack.com/api/files.upload"
querystring = {"token":slack_token}
payload = { "channels":slack_channel}
file_upload = { "file":(filename, open(filename, 'rb'),filetype) }
headers = { "Content-Type": "multipart/form-data", }
response = requests.post(url, data=payload, params=querystring, files=file_upload)
def getStatuscode(url):
try:
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
r = requests.get(url, headers=headers, verify=False,timeout=25, allow_redirects=False) # it is faster to only request the header
soup = BeautifulSoup(r.text)
metas = soup.find_all('meta')
description=[ meta.attrs['content'] for meta in metas if 'name' in meta.attrs and meta.attrs['name'] == 'description' ]
if len(description)>0:
des=1
else:
des=-1
return r.status_code,des
except:
return -1,-1
def is_valid(url):
"""
Checks whether `url` is a valid URL.
"""
parsed = urlparse(url)
return bool(parsed.netloc) and bool(parsed.scheme)
def get_all_website_links(url):
"""
Returns all URLs that is found on `url` in which it belongs to the same website
"""
# all URLs of `url`
internal_urls = list()
# domain name of the URL without the protocol
domain_name = urlparse(url).netloc
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.169 Safari/537.36'}
r_content = requests.get(url, headers=headers, verify=False, timeout=25, allow_redirects=False).content
soup = BeautifulSoup(r_content, "html.parser")
for a_tag in soup.findAll("a"):
href = a_tag.attrs.get("href")
#print(a_tag.string)
if href == "" or href is None:
# href empty tag
continue
# join the URL if it's relative (not absolute link)
href = urljoin(url, href)
parsed_href = urlparse(href)
# remove URL GET parameters, URL fragments, etc.
href = parsed_href.scheme + "://" + parsed_href.netloc + parsed_href.path
if not is_valid(href):
# not a valid URL
continue
if href in internal_urls:
# already in the set
continue
if domain_name not in href:
# external link
continue
internal_urls.append([href,a_tag.string])
return internal_urls
def get_sitemap_urls(site):
sitemap = adv.sitemap_to_df(site)
sitemap_urls = sitemap['loc'].dropna().to_list()
return sitemap_urls
def sitemap_internallink_status_code_checker(site,SLEEP,slack_token,slack_channel):
print("Start scrapping internal links for all sitemap urls")
sitemap_urls = get_sitemap_urls(site)
sub_links_dict = dict()
for url in sitemap_urls:
sub_links = get_all_website_links(url)
sub_links_dict[url] = list(sub_links)
print("checking status code and description")
scrapped_url=dict()
description_url=dict()
url_statuscodes = []
for link in sub_links_dict.keys():
int_link_list=sub_links_dict[link]
for int_link in int_link_list:
internal_link=int_link[0]
#print(internal_link)
linktext=int_link[1]
#print(linktext)
if internal_link in scrapped_url.keys():
check = [link,internal_link,linktext,scrapped_url[internal_link],description_url[internal_link]]
else:
linkstatus,descriptionstatus=getStatuscode(internal_link)
scrapped_url[internal_link]=linkstatus
description_url[internal_link]=descriptionstatus
check = [link,internal_link,linktext,linkstatus,descriptionstatus]
time.sleep(SLEEP)
url_statuscodes.append(check)
url_statuscodes_df=pd.DataFrame(url_statuscodes,columns=["url","internal_link","link_text","status_code","description_status"])
#check status code for all sitemap urls
sitemap_statuscodes=[]
for url in sitemap_urls:
if url in scrapped_url.keys():
check=[url,scrapped_url[url]]
else:
linkstatus,descriptionstatus=getStatuscode(url)
check=[url,linkstatus]
time.sleep(SLEEP)
sitemap_statuscodes.append(check)
sitemap_statuscodes_df=pd.DataFrame(sitemap_statuscodes,columns=["url","status_code"])
# statitics and then send to slack
strstatus=""
df_internallink_status=url_statuscodes_df[url_statuscodes_df["status_code"]!=200]
if len(df_internallink_status)>0:
df_internallink_status=df_internallink_status[["url","internal_link","link_text","status_code"]]
df_internallink_status["status_group"]=(df_internallink_status['status_code'] / 100).astype(int) *100
for status in df_internallink_status["status_group"].unique():
ststatus=f'{status}'
noUrls=len(df_internallink_status[df_internallink_status["status_group"]==status])
sts=ststatus[:-1] + 'X'
if sts=='X':
sts="-1"
strstatus=f">*{noUrls}* internal link with status code *{sts}*\n" + strstatus
df_internallink_status=df_internallink_status[["url","internal_link","link_text","status_code"]]
df_internallink_status.to_csv("internallinks.csv",index=False)
else:
strstatus=">*Great news!*, There is no internal links with bad status code\n"
strdescription=""
df_description=url_statuscodes_df[url_statuscodes_df["description_status"]==-1]
if len(df_description)>0:
df_description=df_description[["internal_link","status_code","description_status"]]
df_description=df_description.drop_duplicates(subset = ["internal_link"])
df_description.rename(columns={'internal_link': 'url'}, inplace=True)
df_description.to_csv("linksdescription.csv",index=False)
lendesc=len(df_description)
strdescription=f">*{lendesc}* url that don't have *meta description*.\n"
else:
strdescription=">*Great news!*, There is no url that don't have *meta description*\n"
sitemapstatus=""
df_sitemap_status=sitemap_statuscodes_df[sitemap_statuscodes_df["status_code"]!=200]
if len(df_sitemap_status)>0:
df_sitemap_status=df_sitemap_status[["url","status_code"]]
df_sitemap_status["status_group"]=(df_sitemap_status['status_code'] / 100).astype(int) *100
for status in df_sitemap_status["status_group"].unique():
ststatus=f'{status}'
noUrls=len(df_sitemap_status[df_sitemap_status["status_group"]==status])
sts=ststatus[:-1] + 'X'
if sts=='X':
sts="-1"
sitemapstatus=f">*{noUrls}* url with status code *{sts}*\n" + sitemapstatus
df_sitemap_status=df_sitemap_status[["url","status_code"]]
df_sitemap_status.to_csv("sitemaplinks.csv",index=False)
else:
sitemapstatus=">*Great news!*, There is no url in sitemap with bad status code\n"
if (len(df_sitemap_status) + len(df_internallink_status) + len(df_description))>0:
message=f"After analysing {site} sitemap: \n"+strstatus+strdescription+sitemapstatus+"For more details see the attachement files."
else:
message=f"After analysing {site} sitemap: \n"+strstatus+strdescription+sitemapstatus
print("send slack notifications")
#send notification to slack
slack_notification_message(slack_token,slack_channel,message)
if len(df_sitemap_status)>0:
slack_notification_file(slack_token,slack_channel,"sitemaplinks.csv","text/csv")
if len(df_internallink_status)>0:
slack_notification_file(slack_token,slack_channel,"internallinks.csv","text/csv")
if len(df_description)>0:
slack_notification_file(slack_token,slack_channel,"linksdescription.csv","text/csv")
# Enter your XML Sitemap
sitemap = "https://www.pemavor.com/sitemap.xml"
SLEEP = 0.5 # Time in seconds the script should wait between requests
#-------------------------------------------------------------------------
# Enter your slack OAutch token here
slack_token = "XXXX-XXXXXXXX-XXXXXX-XXXXXXX"
# Change slack channel to your target one
slack_channel= "SEO Monitoring"
sitemap_internallink_status_code_checker(sitemap,SLEEP,slack_token,slack_channel)
Where to run and schedule your Python scripts
- In real production environments, we recommend hosting your script somewhere in the Cloud. We use Cloud Functions or Cloud Runs that are triggered with Pub/Sub.
- A more simple approach is to use a small virtual server that all big web hosting services provide. They normally run on Linux. You can add your Python code there and schedule it using the good old crontab.
- If you have fun with hacking around, you could also use a RaspberryPi and run your own Linux based 24×7 home server. It’s affordable (around $60) and small, so you can place and hide it easily somewhere.
