
- Book Club: The DevOps Handbook (Conclusion)
- Book Club: The DevOps Handbook (Chapter 11. Enable and Practice Continuous Integration)
- Book Club: The DevOps Handbook (Chapter 1. Agile, Continuous Delivery, and the Three Ways)
- Book Club: The DevOps Handbook (Chapter 2. The First Way: The Principles of Flow)
- Book Club: The DevOps Handbook (Chapter 3. The Second Way: The Principles of Feedback)
- Book Club: The DevOps Handbook (Chapter 4. The Third Way: The Principles of Continual Learning and Experimentation)
- Book Club: The DevOps Handbook (Chapter 5. Selecting Which Value Stream to Start With)
- Book Club: The DevOps Handbook (Chapter 6. Understanding the Work in Our Value Stream, Making it Visible, and Expanding it Across the Organization)
- Book Club: The DevOps Handbook (Chapter 7. How to Design Our Organization and Architecture with Conway’s Law in Mind)
- Book Club: The DevOps Handbook (Chapter 8. How to Get Great Outcomes by Integrating Operations into the Daily Work of Development)
- Book Club: The DevOps Handbook (Chapter 9. Create the Foundations of our Deployment Pipeline )
- Book Club: The DevOps Handbook (Chapter 10. Enable Fast and Reliable Automated Testing)
- Book Club: The DevOps Handbook (Chapter 12. Automate and Enable Low-Risk Releases)
- Book Club: The DevOps Handbook (Chapter 23. Protecting the Deployment Pipeline and Integrating Into Change Management and Other Security and Compliance Controls)
- Book Club: The DevOps Handbook (Chapter 13. Architect for Low-Risk Releases)
- Book Club: The DevOps Handbook (Chapter 14. Create Telemetry to Enable Seeing and Solving Problems)
- Book Club: The DevOps Handbook (Chapter 15. Analyze Telemetry to Better Anticipate Problems and Achieve Goals)
- Book Club: The DevOps Handbook (Chapter 16. Enable Feedback So Development and Operations Can Safely Deploy Code)
- Book Club: The DevOps Handbook (Chapter 17. Integrate Hypothesis-Driven Development and A/B Testing into Our Daily Work)
- Book Club: The DevOps Handbook (Chapter 18. Create Review and Coordination Processes to Increase Quality of Our Current Work)
- Book Club: The DevOps Handbook (Chapter 19. Enable and Inject Learning into Daily Work)
- Book Club: The DevOps Handbook (Chapter 20. Convert Local Discoveries into Global Improvements)
- Book Club: The DevOps Handbook (Chapter 21. Reserve Time to Create Organizational Learning and Improvement)
- Book Club: The DevOps Handbook (Chapter 22. Information Security as Everyone’s Job, Every Day)
- Book Club: The DevOps Handbook (Introduction)
The following is a chapter summary for “The DevOps Handbook” by Gene Kim, Jez Humble, John Willis, and Patrick DeBois for an online book club.
The book club is a weekly lunchtime meeting of technology professionals. As a group, the book club selects, reads, and discuss books related to our profession. Participants are uplifted via group discussion of foundational principles & novel innovations. Attendees do not need to read the book to participate.
Background on The DevOps Handbook
More than ever, the effective management of technology is critical for business competitiveness. For decades, technology leaders have struggled to balance agility, reliability, and security. The consequences of failure have never been greater―whether it’s the healthcare.gov debacle, cardholder data breaches, or missing the boat with Big Data in the cloud.
And yet, high performers using DevOps principles, such as Google, Amazon, Facebook, Etsy, and Netflix, are routinely and reliably deploying code into production hundreds, or even thousands, of times per day.
Following in the footsteps of The Phoenix Project, The DevOps Handbook shows leaders how to replicate these incredible outcomes, by showing how to integrate Product Management, Development, QA, IT Operations, and Information Security to elevate your company and win in the marketplace.
The DevOps Handbook
Chapter 10
Teams are likely to get undesired outcomes if they find and fix errors in a separate test phase, executed by a separate QA department only after all development has been completed. Teams should Continuously Build, Test, and Integrate Code Environments.
“Without automated testing, the more code we write, the more time and money is required to test our code—in most cases, this is a totally unscalable business model for any technology organization.”
– Gary Gruver, The DevOps Handbook (Chapter 10)
Google’s own success story on automated testing:
- 40,000 code commits/day
- 50,000 builds/day (on weekdays, this may exceed 90,000)
- 120,000 automated test suites
- 75 million test cases run daily
- 100+ engineers working on the test engineering, continuous integration, and release engineering tooling to increase developer productivity (making up 0.5% of the R&D workforce)
Continuously Build, Test, and Integrate Code & Environments
Create automated test suites that increase the frequency of integration and testing of the code and the environments from periodic to continuous.
The deployment pipeline, first defined by Jez Humble and David Farley in their book Continuous Delivery: Reliable Software Releases Through Build, Test, and Deployment Automation, ensures that all code checked in to version control is automatically built and tested in a production-like environment.
Create automated build and test processes that run in dedicated environments. This is critical for the following reasons:
- The build and test process can run all the time, independent of the work habits of individual engineers.
- A segregated build and test process ensures that teams understand all the dependencies required to build, package, run, and test the code.
- Packaging the application to enable repeatable installation of code and configurations into an environment.
- Instead of putting code in packages, teams may choose to package applications into deployable containers.
- Environments can be made more production-like in a way that is consistent and repeatable.
The deployment pipeline validates after every change the code successfully integrates into a production-like environment. It becomes the platform through which testers request & certify builds during acceptance testing; the pipeline will run automated performance and security validations.
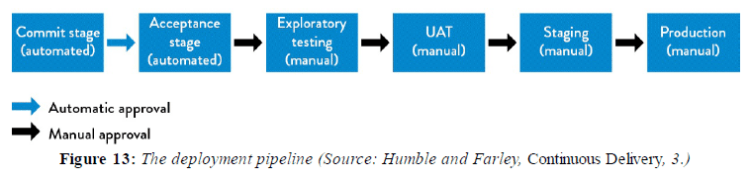
The goal of a deployment pipeline is to provide everyone in the value stream the fastest possible feedback whether a change is successful or not. Changes could be to the code, any environments, automated tests, or the deployment pipeline infrastructure.
A continuous integration practice requires three capabilities:
- A comprehensive and reliable set of automated tests that validate the application is in a deployable state.
- A culture that “stops the entire production line” when the validation tests fail.
- Developers working in small batches on trunk rather than long-lived feature branches.
Build a Fast and Reliable Automated Validation Test Suite
Unit Tests: These test a single method, class, or function in isolation, providing assurance to the developer that their code operates as designed. Unit tests often “stub out” databases and other external dependencies.
Acceptance Tests: These test the application as a whole to provide assurance that a higher level of functionality operates as designed and that regression errors have not been introduced.
Humble and Farley define the difference between unit and acceptance testing as, “The aim of a unit test is to show that a single part of the application does what the programmer intends it to… the objective of acceptance tests is to prove that our application does what the customer meant it to, not that it works the way its programmers think it should.”
After a build passes unit tests, the deployment pipeline runs the build against acceptance tests. Any build that passes acceptance tests is then typically made available for manual testing.
Integration Tests: Integration tests ensure that the application correctly interacts with other production applications and services, as opposed to calling stubbed out interfaces.
As Humble and Farley observe, “Much of the work in the SIT environment involves deploying new versions of each of the applications until they all cooperate. In this situation the smoke test is usually a fully fledged set of acceptance tests that run against the whole application.”
Integration tests are performed on builds that have passed both the unit and acceptance test suites. Since integration tests are often brittle, teams should minimize the number of integration tests and find defects during unit & acceptance testing. The ability to use virtual or simulated versions of remote services when running acceptance tests becomes an essential architectural requirement.
Catch Errors As Early In The Automated Testing as Possible
For the fastest feedback, it’s important to run faster-running automated tests (unit tests) before slower-running automated tests (acceptance and integration tests), which are both run before any manual testing. Another corollary of this principle is that any errors should be found with the fastest category of testing possible.

Ensure Tests Run Quickly
Design tests to run in parallel.

Write Automated Tests Before Writing The Code
Use techniques such as test-driven development (TDD) and acceptance test-driven development (ATDD). This is when developers begin every change to the system by first writing an automated test that validates the expected behavior fails and then writes the code to make the tests pass.
Test-Driven Development:
- Ensure the tests fail. “Write a test for the next bit of functionality to add.” Check in.
- Ensure the tests pass. “Write the functional code until the test passes.” Check in.
- “Refactor both new and old code to make it well structured.” Ensure the tests pass. Check in again.
Automate As Many Of The Manual Tests As Possible
Automating all the manual tests may create undesired outcomes – teams should not have automated tests that are unreliable or generate false positives (tests that should have passed because the code is functionally correct but failed due to problems such as slow performance, causing timeouts, uncontrolled starting state, or unintended state due to using database stubs or shared test environments).
A small number of reliable, automated tests are preferable over a large number of manual or unreliable automated tests. Start with a small number of reliable automated tests and add to them over time, creating an increasing level of assurance that any changes to the system that take the application out of a deployable state is detected.
Integrate Performance Testing Into The Test Suite
All too often, teams discover that their application performs poorly during integration testing or after it has been deployed to production. The goal is to write and run automated performance tests that validate the performance across the entire application stack (code, database, storage, network, virtualization, etc.) as part of the deployment pipeline to detect problems early when the fixes are cheapest and fastest.
By understanding how the application and environments behave under a production-like load, the team can improve at capacity planning as well as detecting conditions such as:
- When the database query times grow non-linearly.
- When a code change causes the number of database calls, storage use, or network traffic to increase.
Integrate Non-Functional Requirements Testing Into The Test Suite
In addition to testing the code functions as designed and it performs under production-like loads, teams should validate every other attribute of the system. These are often called non-functional requirements, which include availability, scalability, capacity, security, etc..
Many nonfunctional requirements rely upon:
- Supporting applications, databases, libraries, etc.
- Language interpreters, compilers, etc.
- Operating systems
Pull The Andon Cord When The Deployment Pipeline Breaks
In order to keep the deployment pipeline in a green state the team should create a virtual Andon Cord, similar to the physical one in the Toyota Production System. Whenever someone introduces a change that causes the build or automated tests to fail, no new work is allowed to enter the system until the problem is fixed.
When the deployment pipeline is broken, at a minimum notify the entire team of the failure, so anyone can either fix the problem or rollback the commit. Every member of the team should be empowered to roll back the commit to get back into a green state.
Why Teams Need To Pull The Andon Cord
The consequence of not pulling the Andon cord and immediately fixing any deployment pipeline issues makes it more difficult to bring applications and environment back into a deployable state.
Consider the following situation:
- Someone checks in code that breaks the build or fails automated tests, but no one fixes it.
- Someone else checks in another change onto the broken build, which also doesn’t pass the automated tests; however, no one sees the failing test results which would have enabled the team to see the new defect, let alone fix it.
- The existing tests don’t run reliably, so the team is unlikely to build new tests.
- The negative feedback cycle continues and application quality continues to degrade.