Introduction
A popular task is to identify the greatest hitting season of a batter in MLB history. Here we focus on one good measure of batting performance, the weighted on-base percentage wOBA. One could simply list the highest wOBA player-seasons, but there are some questions on using this leaderboard to identify “best” hitters.
- (Distinction between Performance and Ability) There is a distinction between a player’s hitting performance, measured by wOBA, and his unknown batting ability, measured by, say
. (Statisticians like to use greek letters to describe unknown quantities.). If a player has a relatively small number of plate appearances (PA), then wOBA isn’t an accurate measurement of his ability
- (Comparing Across Seasons?) It is challenging to compare players’ wOBA values across different seasons since the hitting environments for the two seasons can be different. A wOBA of .320 in Season X actually might be more impressive than a wOBA of .340 in Season Y, since it was harder to score runs in Season X.
- (What is Best?) Instead of comparing raw wOBA season values, it seems better to focus on how a batter performs relative to players in a particular season. In other words, who were the hitters that stood out most compared to other hitters in the same season?
In this post, we identify the players who were the most outlying among all players in the same season. We first fit a popular multilevel model on the wOBA measures — that gives us a handle on the distribution of wOBA abilities in that season. Then we use a predictive standardized residual to measure the extremeness of a particular wOBA performance. By ranking these predictive residuals, we identify the 24 most-outlying wOBA season values during the 1960-2023 period,
Data
Fangraphs provides a convenient source of season batting statistics. From the Major League Leaders page, I select seasons 1960 through 2023, split the seasons, and focus on batters with at least 100 plate appearances. From the Fangraphs dashboard, I see a list of 24,739 batter seasons with a group of common measures that I can download in a single csv file.
The Model
Suppose we collect all of the wOBA measures for a single season. For the sampling model, let the 
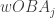
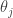





By using the Retrosheet data for a single season, one can get a good estimate of the sampling standard deviation 
Predictive Residual
In the case where 


For a given season, most of the 
Results
For a season, we collect the wOBA values for all players with at least 100 PA. For each season (from 1960 through 2023), we fit this multilevel model, estimate the parameters
If we list the top-10 season wOBA values in this 1960 to 2023 period, we get this list.
Season Name PA wOBA resid
<dbl> <chr> <dbl> <dbl> <dbl>
1 2002 Barry Bonds 612 0.544 5.22
2 2004 Barry Bonds 617 0.537 5.31
3 2001 Barry Bonds 664 0.537 4.91
4 2003 Barry Bonds 550 0.503 4.14
5 1968 Gates Brown 104 0.502 3.26
6 1994 Frank Thomas 517 0.499 3.95
7 2000 Mark McGwire 321 0.494 3.19
8 1998 Mark McGwire 681 0.492 3.87
9 1993 Mark McGwire 107 0.492 2.73
10 1996 Mark McGwire 548 0.489 3.49
Instead, if we list the top predictive Z scores, we get this list:
Season Name PA wOBA resid
<dbl> <chr> <dbl> <dbl> <dbl>
1 2004 Barry Bonds 617 0.537 5.31
2 2002 Barry Bonds 612 0.544 5.22
3 2001 Barry Bonds 664 0.537 4.91
4 2022 Aaron Judge 696 0.458 4.32
5 2003 Barry Bonds 550 0.503 4.14
6 2015 Bryce Harper 654 0.461 4.04
7 1994 Frank Thomas 517 0.499 3.95
8 1980 George Brett 515 0.478 3.90
9 1997 Larry Walker 664 0.488 3.89
10 1998 Mark McGwire 681 0.492 3.87
Clearly Barry Bonds dominates both leaderboards with his four remarkable seasons in 2001 through 2004. But there are some interesting differences between the two lists:
- Mark McGwire’s accomplishments are not as impressive when expressed on this predictive residual scale. He is listed four times on the first list, but only once on the second list.
- Aaron Judge is nowhere to be found on the first list, but his 2022 season ranks fourth on the predictive residual list.
- There are several interesting new players like Bryce Harper, George Brett and Larry Walker on this predictive residual list.
A Graph
Suppose we look at the top 24 hitter/seasons where the predictive residual exceeds 3.4. I have displayed a scatterplot of these top residuals as a function of the season, labeling the point with the player name. Certainly, Barry Bonds stands out for three seasons, but many of the other residuals are similar in size. So, for example, Miguel Cabrera’s wOBA of .455 in 2013 is comparable to Mike Schmidt’s wOBA value of .467 in 1981.

Concluding Comments
Let’s explain how we addressed each of our initial concerns about the leaderboard of the raw wOBA values and give some details about the R work.
- In our model, we make a distinction between performance and ability — in our multilevel model, we assume that the wOBA abilities for a given season follow a normal curve.
- The predictive distribution is useful in predicting a future wOBA — it allows for variation both in the wOBA ability and the observed wOBA performance. We measure extremeness by seeing how the observed wOBA compares to this predictive distribution of wOBA measures in the same season. A .340 wOBA may be extreme for one season and not extreme for another season.
- It is challenging to compare accomplishments, especially when the seasons are far apart. How does Babe Ruth compare with Barry Bonds? That is difficult to answer, but this method focuses on how Ruth or Bonds performed relative to their contemporaries.
- This approach can be used for any measure of batting performance. It is reasonable to assume that batting abilities of players are normally distributed. One can fit a multilevel model to the performances and use some predictive measure to identify the extremeness of a particular performance. I think this approach levels the playing field and makes it easier to compare accomplishments across different seasons.
- Most of the R work in this particular post is straightforward to implement. I’m using the
laplace()function in theLearnBayespackage to fit this normal-normal multilevel model.
