

Keeping tests valuable: Using Equivalence Class Partition and Boundary Value Analysis.
Pretty good testing is easy to do... Excellent testing is quite hard to do. — James Bach




Writing tests that aggregate value is important for any application. Testing improves the quality of software. But for our tests to continue or become valuable, we need to learn more and more about how to improve them. The focus of this post is how to write tests that care about boundaries. To do this we will understand two techniques that go hand in hand, boundary value analysis and equivalence partitioning. Let's look at an example before we delve into these topics.
The phone field example
Let's take a very common case in our daily life as developers. Imagine you are working on a form, we need to validate a phone field. The requirements determined for this field that need to be applied are:
It must be between 11 and 13 digits long. Nothing below 11 digits is allowed, and nothing above 13 digits either.
It must have only numbers, no letters are allowed.
Cannot be null.
Nice, we have the requirements for building the code. But we also practically have our test cases. But we stop there? We can go further and think of cases, situations, and what would happen if the user sends this value. What if we try phone numbers with exactly 11 digits and 13 digits? If the developer forgot to validate it, it would probably be a scenario to consider. An input with an invalid value, such as string only, should never pass. But what if in that input you type null?
All these scenarios can and should be taken into consideration when writing tests. Note that these are possible behaviors, not class implementation details. What we are interested in here are inputs and outputs.
What does equivalence class partition mean?
Confusing name? The goal of this technique involves dividing the input test data into separate partitions with similar elements. This is a technique that can be used at any level of software testing. When we say similar elements, we mean partitions that have valid or invalid input data sets, in the phone field example we have partitions that are between 11, 12 and 13 that are valid inputs for the rule. But we also have invalid partitions, for example, 10 and 14. The definition says that we need to divide the test data into separate partitions with similar elements. Not clear? Another example is if you need to test an input box that accepts numbers from 1 to 1,000, there is no point in writing thousands of test cases for all 1,000 valid input numbers, plus other test cases for invalid data. Using the Equivalence Partition method, the test cases can be divided into sets of input data called classes. Each test case is representative of its respective class.
The assumption behind this approach is that if a condition/value in one partition passes, all the others will also pass. Likewise, if one condition in a partition fails, all other conditions in that partition will fail.
This is one of the main advantages of boundary value analysis, which is the ability to reduce a very large number of test cases to manageable pieces.
See the illustration below that demonstrates the phone field case:

What is Boundary Value Analysis?
BVA is used for finding the bugs at the boundaries of the input domain (tests the behavior of a program at the input boundaries) instead of finding those bugs at the center of the input. The name comes from Boundary, which means the boundaries of an area. Therefore, BVA focuses mainly on testing valid and invalid input parameters for a given range of a software components.
Trying to simplify a bit more, the boundary value simply implies identifying the boundary conditions for whatever application, component, or logic you are testing.
So as we saw, if the rule that a valid phone number requires it to be 11 and 13 digits, will need to test with a phone number with 10 digits, 11 digits, 13 digits and 14 digits. This is the only way to understand well how our class, and method, behave near limits. Why do we say that Boundary Value Analysis and equivalence partitions go hand in hand? Because one complements the other. If we analyze now we can bring the two techniques together to understand the boundaries of each behavior that needs to be tested. See this illustration:

Let's look at this a little more in practice.
The main difference between the two techniques is that with BVA we can find errors that occur at the boundaries of the input domain. Boundary value analysis is used to identify errors at the boundaries, rather than finding those that exist in the center of the input domain.
Bugs like to hide in boundaries
In the example of the phone field, we can then start our tests by focusing on the behavior but also trying to check its limits. See the example in very basic code, so don't focus on the implementation of the method but rather on what we are going to test:
public class Phone {
public boolean isValid(String phone) {
if (phone == null) return false;
if(!phone.matches("[0-9]+")) {
return false;
}
if (phone.length() < 11) {
return false;
}
if (phone.length() > 13) {
return false;
}
return true;
}
public Phone() {
}
}
Now let's get to testing:
import org.junit.Test;
import static org.assertj.core.api.Assertions.assertThat;
public class PhoneTest {
@Test
public void phone_Should_Return_False_If_Contain_Letters() {
Phone phone = new Phone();
assertThat(phone.isValid("12345678902s")).isFalse();
}
@Test
public void phone_Should_Return_False_If_Contain_14_Digits() {
Phone phone = new Phone();
assertThat(phone.isValid("12345678902134")).isFalse();
}
@Test
public void phone_Should_Return_False_If_Contain_10_Digits() {
Phone phone = new Phone();
assertThat(phone.isValid("1234567890")).isFalse();
}
@Test
public void phone_Should_Return_False_If_Phone_Is_Null() {
Phone phone = new Phone();
assertThat(phone.isValid(null)).isFalse();
}
@Test
public void phone_Should_Return_True_If_Contain_At_Least_11_Digits() {
Phone phone = new Phone();
assertThat(phone.isValid("12345678902")).isTrue();
}
@Test
public void phone_Should_Return_True_If_Contain_At_Most_13_Digits() {
Phone phone = new Phone();
assertThat(phone.isValid("1234567890213")).isTrue();
}
}
These tests are pretty simple and go through the bounds. Why is boundary testing important? What value does it add to the software? Let's go through the code again, but now refactoring the class:
public class Phone {
public boolean isValid(String phone) {
if (phone == null) return false;
return phone.matches("[0-9]+") && phone.length() > 11 && phone.length() < 13;
}
public Phone() {
}
}
What is expected after this refactoring? That the tests continue to run without fail. No behavior has been changed... or has it? Let's run the tests:
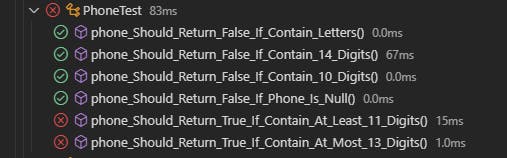
The two tests that failed:
Phone must contain at least 11 digits
Phone must contain at most 13 digits
These tests show that during refactoring the behavior at the boundaries was changed. You see, it seems that if the user now passes in the input a phone value with up to 11 digits, this will be invalid, whereas the requirement says the opposite. The phone must contain at least 11 digits. So what happened during refactoring? Take a look at the class code:
return phone.matches("[0-9]+") && phone.length() > 11 && phone.length() < 13;
See how these tests avoid bugs that can cost a few hours? Testing the boundaries is very important, especially to be able to understand behavior breaks in your application boundaries! The logical operator = is missing, this occurred during refactoring. So when the input was inserted and the test was executed, the test failed because the values were equal, but there was no treatment for this, 11 is greater than 11? No! But as there is no operator to validate, the method will return false. The same case occurs for the 13 digits test. Probably QA could find this bug. This phone field scenario proves that testing and thinking about all cases and exploring their limits is very important. If the testing didn't exist the field would only accept 12 digits. If there was a test with only 12 digits the developer would probably imagine that everything was ok after the refactoring, because this test would pass. Every time the user would enter 11 and 13 digits, the user would probably see error messages on the screen.
Let's adjust and see if everything works now:
public class Phone {
public boolean isValid(String phone) {
if (phone == null) return false;
return phone.matches("[0-9]+") && phone.length() >= 11 && phone.length() <= 13;
}
public Phone() { }
}
// or you can do this in return: phone != null && phone.matches("[0-9]+") && phone.length() >= 11 && phone.length() <= 13;
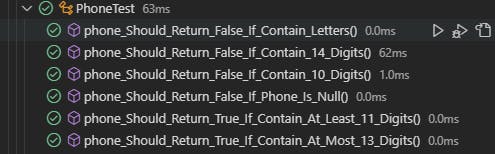
Now everything works correctly and the tests don't break even after a refactoring.
To conclude
Studying techniques to improve the quality of the tests we write is always important. Especially when working with highly complex products that affect the lives of millions of users, bugs can end up destroying our business! We write tests to avoid unexpected behavior and to avoid being surprised by bugs that could be detected if these techniques were applied. I hope this post was useful to help you delve deeper into this topic! Thank you very much for reading, and see you next time!
Books I recommend for digging deeper and improving the way you think about and write software testing: