
{kind=link}
Right now, I can open up Google Photos, type "beach," and see my photos from various beaches I've visited over the last decade. I never went through my photos and labeled them; instead, Google identifies beaches based on the contents of the photos themselves. This seemingly mundane feature is based on a technology called deep convolutional neural networks, which allows software to understand images in a sophisticated way that wasn't possible with prior techniques.
In recent years, researchers have found that the accuracy of the software gets better and better as they build deeper networks and amass larger data sets to train them. That has created an almost insatiable appetite for computing power, boosting the fortunes of GPU makers like Nvidia and AMD. Google developed its own custom neural networking chip several years ago, and other companies have scrambled to follow Google's lead.
Over at Tesla, for instance, the company has put deep learning expert Andrej Karpathy in charge of its Autopilot project. The carmaker is now developing a custom chip to accelerate neural network operations for future versions of Autopilot. Or, take Apple: the A11 and A12 chips at the heart of recent iPhones include a "neural engine" to accelerate neural network operations and allow better image- and voice-recognition applications.
Experts I talked to for this article trace the current deep learning boom to one specific paper: AlexNet, nicknamed after lead author Alex Krizhevsky.
"In my mind, 2012 was the milestone year when that AlexNet paper came out," said Sean Gerrish, a machine learning expert and the author of How Smart Machines Think.
Prior to 2012, deep neural networks were something of a backwater in the machine learning world. But then Krizhevsky and his colleagues at the University of Toronto submitted an entry to a high-profile image recognition contest that was dramatically more accurate than anything that had been developed before. Almost overnight, deep neural networks became the leading technique for image recognition. Other researchers using the technique soon demonstrated further leaps in image recognition accuracy.
In this piece we'll dig deep into deep learning. I'll explain what neural networks are, how they're trained, and why they require so much computing power. And then I'll explain why a particular type of neural network—deep, convolutional networks—is so remarkably good at understanding images. And don't worry—there will be a lot of pictures.
A simple example with a single neuron
The phrase "neural network" may still feel a bit nebulous, so let's start with a simple example. Suppose you want a neural network to decide whether a car should go based on the green, yellow, and red lights of a stoplight. A neural network could accomplish this task with a single neuron.
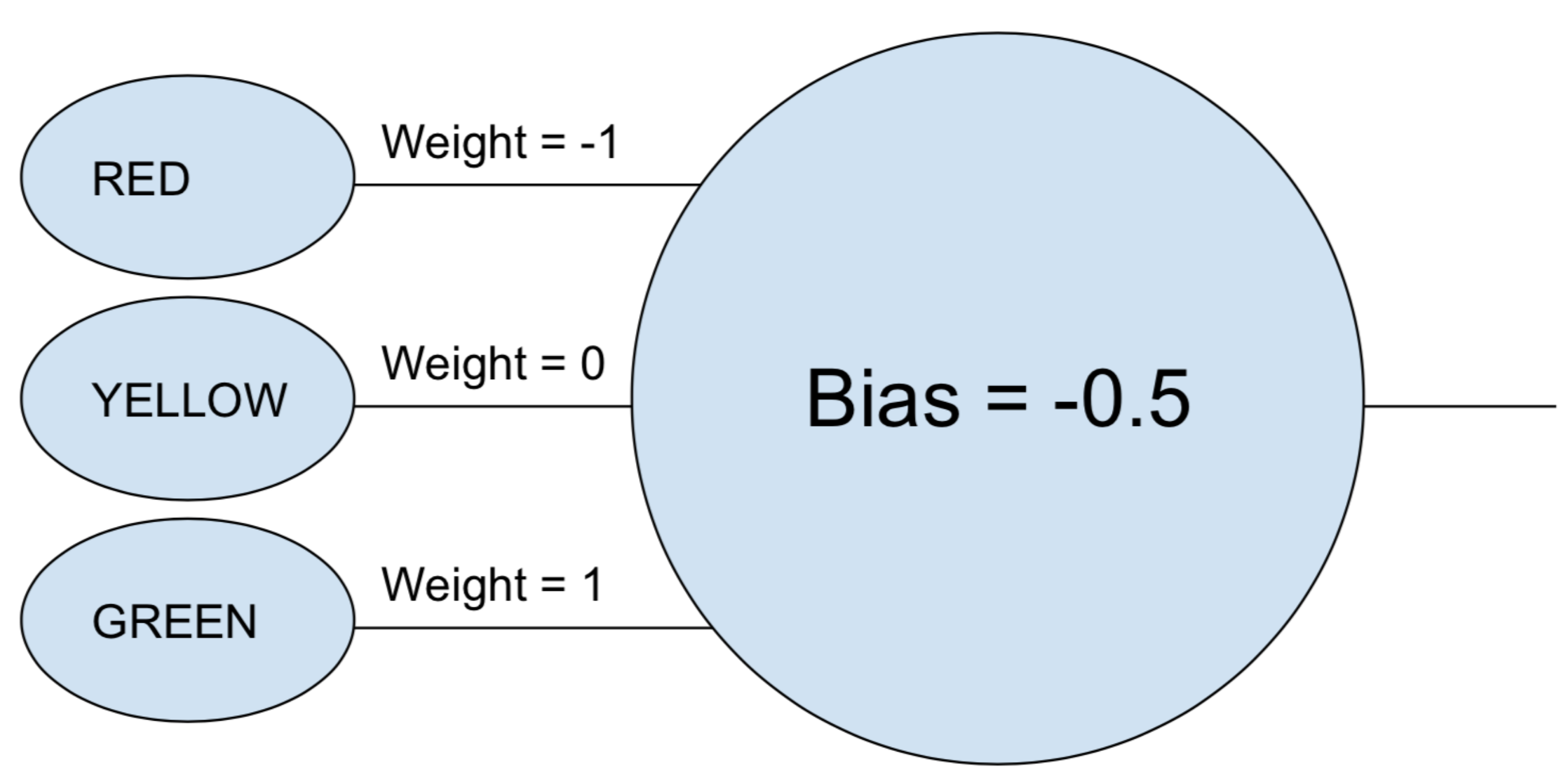
The neuron takes each input (1 for on, 0 for off), multiplies it by its associated weight, and adds all the weighted values together. The neuron then adds the bias, which determines a threshold for the neuron to "activate." In this case, if the output is positive, we consider the neuron to have "fired"—otherwise we don't. This neuron is equivalent to the inequality "green - red - 0.5 > 0." If that evaluates to true—meaning the green light is on and the red light is off—then the car should go.
In real neural networks, artificial neurons take one additional step. After summing the weighted inputs and adding in the bias, the neuron then applies a non-linear activation function. A popular choice is the sigmoid function, an S-shaped function that always produces a value between 0 and 1.
The use of an activation function wouldn't change the result of our simple stoplight model (except we'd need to use a threshold of 0.5 instead of 0). But the nonlinearity of activation functions is essential for enabling neural networks to model more complex functions. Without an activation function, every neural network, no matter how complex, would be reducible to a linear combination of its inputs. And a linear function can't model complex real-world phenomena. Non-linear activation functions make it possible for neural networks to approximate any mathematical function.
An example network
There are lots of ways to approximate functions, of course. What makes neural networks special is that we know how to "train" them using a bit of calculus, a bunch of data, and a whole lot of computing power. Instead of having a human programmer directly design a neural network for a particular task, we can build software that starts with a fairly generic neural network, looks at a bunch of labeled examples, and then modifies the neural network so that it produces the correct label for as many of the labeled examples as possible. The hope is that the resulting network will generalize, producing the correct labels for examples previously not in its training set.
The process to get to this point started well before AlexNet. In 1986, a trio of researchers published a landmark paper about backpropagation, a technique that helped make it mathematically tractable to train complex neural networks.
To get an intuition for how backpropagation works, let's look at a simple neural network described by Michael Nielsen in his excellent online deep learning textbook. The goal of this network is to take a 28×28 pixel image representing a handwritten digit and correctly identify whether the digit is a 0, 1, 2, etc.
Each image has 28×28=784 input values, each a real number between zero and one representing how light or dark a pixel is. Nielsen constructed a neural network that looked like this:
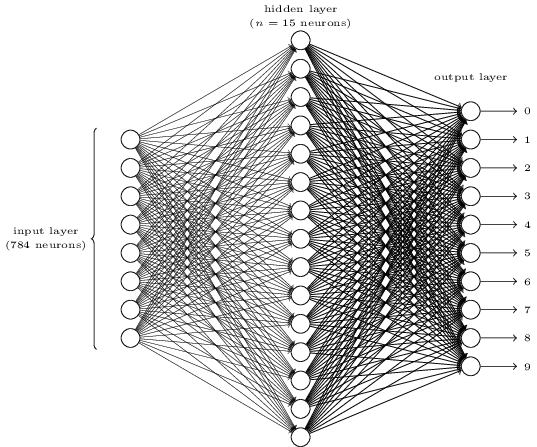
In this image, each of the circles in the middle and right columns is a neuron like the one we looked at in the previous section. Each neuron takes a weighted average of its inputs, adds a bias value, and then applies an activation function. Note that the circles on the left are not neurons—these circles represent the network's input values. While the image only shows 8 input circles, there are actually 784 inputs—one for each pixel in the input images.
Each of the 10 neurons on the right is supposed to "light up" for a different digit: the top neuron should fire when the input image is a handwritten 0 (and not otherwise), the second one should fire when the network sees a handwritten 1 (and not otherwise), and so forth.
Each neuron takes inputs from every neuron in the layer before it. So each of the 15 neurons in the middle layer has 784 input values. Each of these 15 neurons has a weight parameter for each of its 784 inputs. That means this layer alone has 15×784=11,760 weight parameters. Similarly, the output layer contains 10 neurons, each of which takes an input from each of the 15 neurons in the middle layer, adding another 15×10=150 weight parameters. On top of that, the network also has 25 bias variables—one for each of the 25 neurons.
reader comments
153