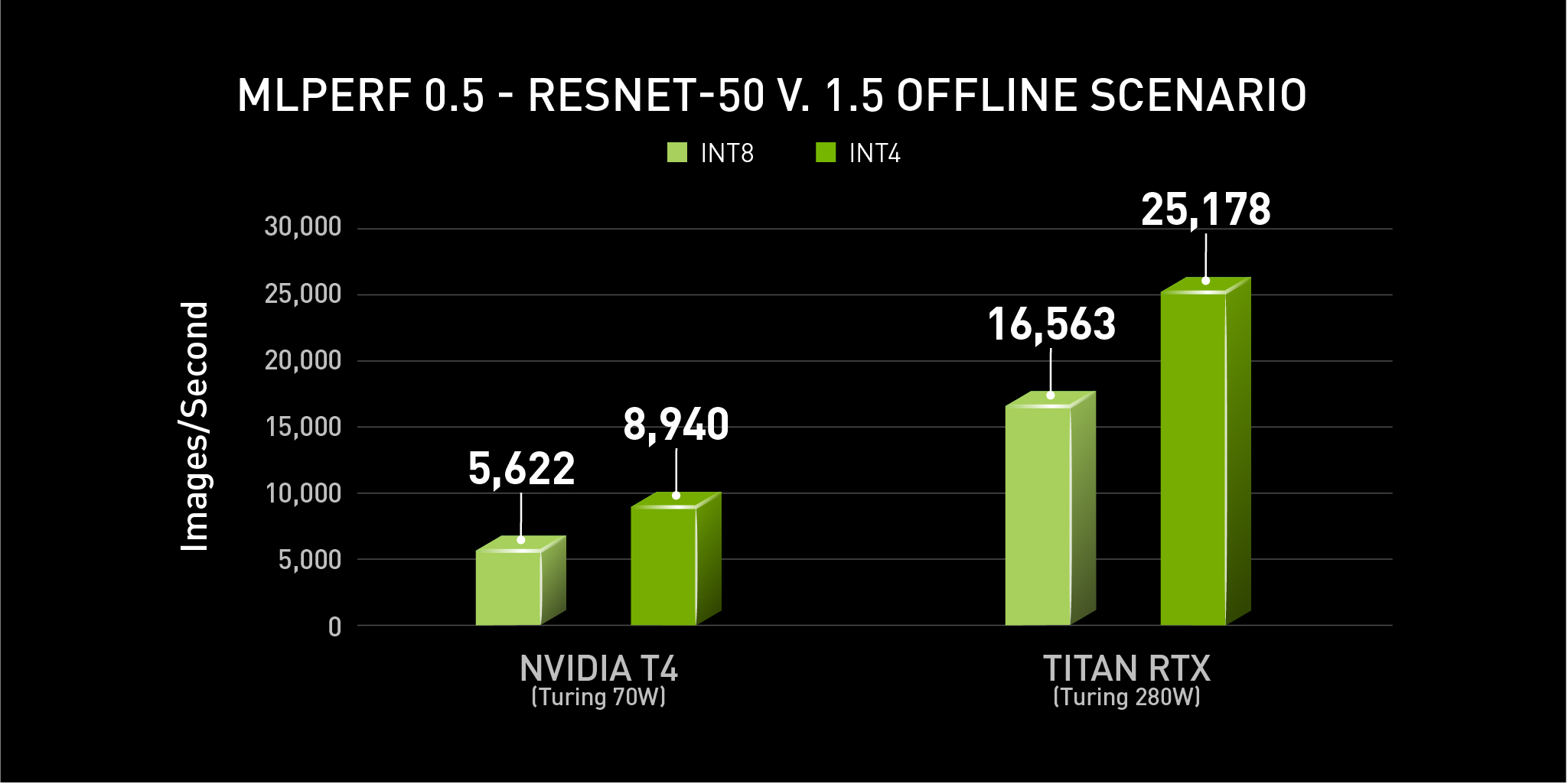
INT4 Precision Can Bring an Additional 59% Speedup Compared to INT8. If there's one constant in AI and deep learning, it's never-ending optimization to wring every possible bit of performance out of a given platform.
Nov 6, 2019
People also ask
What is int8 in deep learning?
What is the dynamic range of int8?
What is integer quantization?
What type of data is used in deep learning?
Jan 27, 2023 � Abstract:Improving the deployment efficiency of transformer-based language models has been challenging given their high computation and�...
Dec 5, 2018 � Yes, this is all about inference. As well as increasing effective computation power, low precision also reduces memory bandwidth - this is as�...
With the decision to use the pruning-quantization order, we trained an INT4 BERT-base model with both 50% and 75% sparsity and reported the best validation�...
Dec 1, 2020 � This INT4 optimization achieves up to a 77% performance boost on real hardware in comparison with the current INT8 solution. December 1st, 2020�...
Aug 25, 2020 � INT4 Precision Can Bring an Additional 59% Speedup Compared to INT8 If there's one constant in AI and deep learning, it's never-ending�...
Naively quantizing a FP32 model to INT4 and lower usually incurs significant accuracy degradation. Many works have tried to mitigate this effect. They usually�...
Jul 23, 2023 � Our INT4 pipeline is 8.5� faster for latency-oriented scenarios and up to 3� for throughput-oriented scenarios compared to the inference of FP16�...
INT4 training is an extremely difficult task, with challenges ranging from numerical format, optimization, model architecture, and software and hardware�...
Experiments combining gradients represented using FP4 with state-of-the-art INT4 techniques for weights and activations demonstrating high accuracy across a�...
