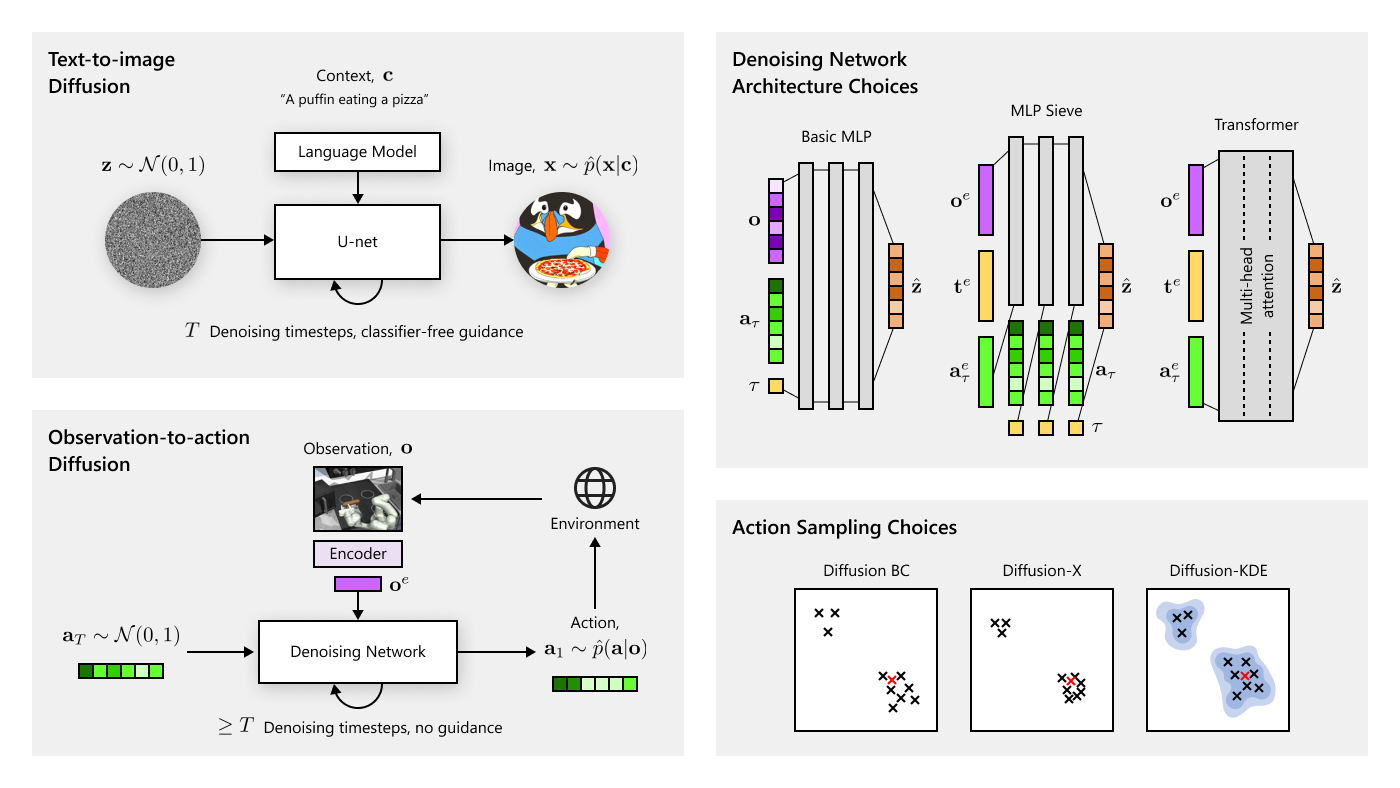
Generating realistic images from a text description is a challenging task for a bot. A solution to this task has potential applications in the video game and image editing industries, among many others. Recently, researchers at Microsoft and elsewhere have been exploring ways to enable bots to draw (opens in new tab) realistic images in defined domains, such as birds, faces or furniture. However, because there is a limited amount of annotated paired image-caption data available, models have difficulty understanding the correspondence between words in the caption to both objects and their interactions. In this new area of research, we explore ways to generate images from text that references several objects, such as “A fire truck stopped in the middle of a quiet street while people pass by on the sidewalk” using dialogue.
A team of researchers from the Montreal Institute for Learning Algorithms (MILA) (opens in new tab) at the University of Montreal and Microsoft Research Montreal (MSR Montreal) (opens in new tab), took inspiration from how sketch artists draw a sketch while conversing with a person who is describing a scene. They hypothesized that giving the bot feedback, in addition to the text, in the form of a dialogue, would help the generation process. For example, the feedback could discuss details about the objects in the caption or even objects not present in the caption.
They tested this hypothesis by pairing images and captions from the Microsoft COCO dataset (opens in new tab) [1] with dialogues for these same images from the Visual Dialog dataset (opens in new tab) [2]. The dialogues in the Visual Dialog dataset were collected by pairing people. The person playing the role of an ‘answerer’ had access to the image and its caption and had to answer questions about the image. The person playing the role of the ‘questioner’ had access only to the image’s caption. The questioner had to ask questions to be able to imagine the scene more clearly.
Microsoft Research Podcast

Collaborators: Holoportation™ communication technology with Spencer Fowers and Kwame Darko
Spencer Fowers and Kwame Darko break down how the technology behind Holoportation and the telecommunication device being built around it brings patients and doctors together when being in the same room isn’t an easy option and discuss the potential impact of the work.
Using the Visual Dialog dataset as an approximation to the sketch artist scenario, the team tested their hypothesis. They observed that conditioning on dialogues helped existing models, such as StackGAN (opens in new tab) [3], to generate higher quality images than the same model architecture conditioned only on captions.

Some images drawn by the ChatPainter model when given a caption and a dialogue

Image generated by the ChatPainter model for a given caption and dialogue
While there is still a long way to go before models can generate realistic images of such complexity, this research represents significant improvement over previous approaches. The team from MSR Montreal believes that in the near future, it will be possible to have conversations with a bot that can generate an image someone has in mind and iteratively refine it from feedback received in the dialogue. This could be useful in animation, interior design, painting and photo refinement among other areas.
The team of researchers is comprised of Shikhar Sharma (opens in new tab) and Samira Ebrahimi Kahou (opens in new tab) from MSR Montreal, and Dendi Suhubdy (opens in new tab), Vincent Michalski (opens in new tab) and Yoshua Bengio (opens in new tab) from MILA.
Read the research paper (opens in new tab) describing the ChatPainter model. To the best of our knowledge, this is the first public research paper to generate images from dialogue data.
References
[1] Lin, T. Y., Maire, M., Belongie, S., Hays, J., Perona, P., Ramanan, D., … & Zitnick, C. L. Microsoft coco: Common objects in context. In European conference on computer vision. Springer, Cham, 2014.
[2] Das, A., Kottur, S., Gupta, K., Singh, A., Yadav, D., Moura, J. M., … & Batra, D. Visual dialog. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Volume 2. 2017.
[3] Zhang, H., Xu, T., Li, H., Zhang, S., Huang, X., Wang, X., & Metaxas, D. Stackgan: Text to photo-realistic image synthesis with stacked generative adversarial networks. IEEE Int. Conf. Comput. Vision. 2017.
Related
- Microsoft researchers build a bot that draws what you tell it to (opens in new tab)
- DA-GAN: Instance-level Image Translation by Deep Attention Generative Adversarial Networks (with Supplementary Materials) (opens in new tab)