Get the most out of Google Kubernetes Engine with Priority and Preemption
Babak Salamat
Software Engineer, Google Kubernetes Engine
David Oppenheimer
Software Engineer, Google Kubernetes Engine
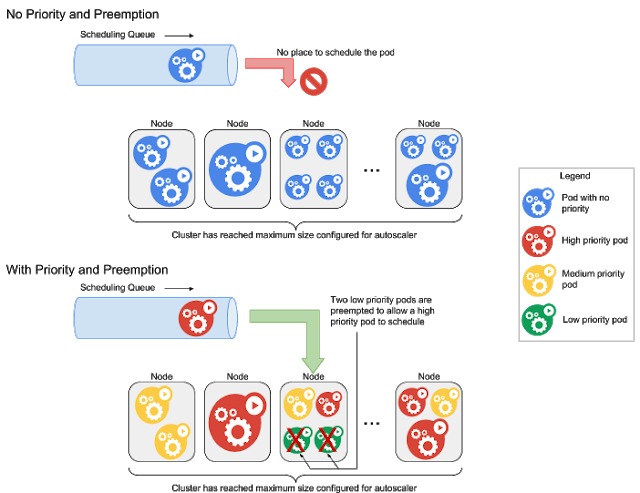
Wouldn’t it be nice if you could ensure that your most important workloads always get the resources they need to run in a Kubernetes cluster? Now you can. Kubernetes 1.9 introduces an alpha feature called “priority and preemption” that allows you to assign priorities to your workloads, so that more important pods evict less important pods when the cluster is full.
Before priority and preemption, Kubernetes pods were scheduled purely on a first-come-first-served basis, and ran to completion (or forever, in the case of pods created by something like a Deployment or StatefulSet). This meant less important workloads could block more important, later-arriving, workloads from running—not the desired effect. Priority and preemption solves this problem.
Priority and preemption is valuable in a number of scenarios. For example, imagine you want to cap autoscaling to a maximum cluster size to control costs, or you have clusters that you can’t grow in real-time (e.g., because they are on-premises and you need to buy and install additional hardware). Or you have high-priority cloud workloads that need to scale up faster than the cluster autoscaler can add nodes. In short, priority and preemption lead to better resource utilization, lower costs and better service levels for critical applications.
Predictable cluster costs without sacrificing safety
In the past year, the Kubernetes community has made tremendous strides in system scalability and support for multi-tenancy. As a result, we see an increasing number of Kubernetes clusters that run both critical user-facing services (e.g., web servers, application servers, back-ends and other microservices in the direct serving path) and non-time-critical workloads (e.g., daily or weekly data analysis pipelines, one-off analytics jobs, developer experiments, etc.). Sharing a cluster in this way is very cost-effective because it allows the latter type of workload to partially or completely run in the “resource holes” that are unused by the former, but that you're still paying for. In fact, a study of Google’s internal workloads found that not sharing clusters between critical and non-critical workloads would increase costs by as much as almost 60 percent. In the cloud, where node sizes are flexible and there's less resource fragmentation, we don’t expect such dramatic results from Kubernetes priority and preemption, but the general premise still holds.The traditional approach to filling unused resources is to run less important workloads as BestEffort. But because the system does not explicitly reserve resources for BestEffort pods, they can be starved of CPU or killed if the node runs out of memory—even if they're only consuming modest amounts of resources.
A better alternative is to run all workloads as Burstable or Guaranteed, so that they receive a resource guarantee. That, however, leads to a tradeoff between predictable costs and safety against load spikes. For example, consider a user-facing service that experiences a traffic spike while the cluster is busy with non-time-critical analytics workloads. Without the priority and preemption capabilities, you might prioritize safety, by configuring the cluster autoscaler without an upper bound or with a very high upper bound. That way, it can handle the spike in load even while it’s busy with non-time-critical workloads. Alternately, you might pick predictability by configuring the cluster autoscaler with a tight bound, but that may prevent the service from scaling up sufficiently to handle unexpected load.
With the addition of priority and preemption, on the other hand, Kubernetes evicts pods from the non-time-critical workload when the cluster runs out of resources, allowing you to set an upper bound on cluster size without having to worry that the serving pipeline might not scale sufficiently to handle the traffic spike. Note that evicted pods receive a termination grace period before being killed, which is 30 seconds by default.
Even if you don’t care about the predictability vs. safety tradeoff, priority and preemption are still useful, because preemption evicts a pod faster than a cloud provider can usually provision a Kubernetes node. For example, imagine there's a load spike to a high-priority user-facing service, so the Horizontal Pod Autoscaler creates new pods to absorb the load. If there are low-priority workloads running in the cluster, the new, higher-priority pods can start running as soon as pod(s) from low-priority workloads are evicted; they don’t have to wait for the cluster autoscaler to create new nodes. The evicted low-priority pods start running again once the cluster autoscaler has added node(s) for them. (If you want to use priority and preemption this way, a good practice is to set a low termination grace period for your low-priority workloads, so the high-priority pods can start running quickly.)
Enabling priority and preemption on Kubernetes Engine
We recently made Kubernetes 1.9 available in Google Kubernetes Engine, and made priority and preemption available in alpha clusters. Here’s how to get started with this new feature:- Create an alpha cluster—please note the cited limitations.
- Follow the instructions to create at least two PriorityClasses in your Kubernetes cluster.
- Create workloads (using Deployment, ReplicaSet, StatefulSet, Job, or whatever you like) with the priorityClassName field filled in, matching one of the PriorityClasses you created.
If you wish, you can also enable the cluster autoscaler and set a maximum cluster size. In that case your cluster will not grow above the configured maximum number of nodes, and higher-priority pods will evict lower-priority pods when the cluster reaches its maximum size and there are pending pods from the higher priority classes. If you don’t enable the cluster autoscaler, the priority and preemption behavior is the same, except that the cluster size is fixed.
Advanced technique: enforcing “filling the holes”
As we mentioned earlier, one of the motivations for priority and preemption is to allow non-time-critical workloads to “fill the resource holes” between important workloads on a node. To enforce this strictly, you can associate a workload with a PriorityClass whose priority is less than zero. Then the cluster autoscaler does not add the nodes necessary for that workload to run, even if the cluster is below the maximum size configured for the autoscaler.Thus you can create three tiers of workloads of decreasing importance:
- Workloads that can access the entire cluster up to the cluster autoscaler maximum size
- Workloads that can trigger autoscaling but that will be evicted if the cluster has reached the configured maximum size and higher-priority work needs to run
- Workloads that will only “fill the cracks” in the resource usage of the higher-priority workloads, i.e., that will wait to run if they can’t fit into existing free resources.
And because PriorityClass maps to an integer, you can of course create many sub-tiers within these three categories.
Let us know what you think!
Priority and preemption are welcome additions in Kubernetes 1.9, making it easier for you to control your resource utilization, establish workload tiers and control costs. Priority and preemption is still an alpha feature. We’d love to know how you are using it, and any suggestions you might have for making it better. Please contact us at kubernetes-sig-scheduling@googlegroups.com.To explore this new capability and other features of Kubernetes Engine, you can quickly get started using our 12-month free trial.


