Migrating to Microservices

The road to microservices is long, winding, and contains many off-ramps to confusing interchanges. Such a journey usually opens with the team heading towards the shining and distant cities known as “Infrastructure Consolidation” and “Operating Cost Reduction.” But in reality, it’s very easy to find yourselves suddenly wandering the jungle of service discovery or the ugly back alleys of Qemu.
Migrating corporate applications and services to the cloud is at the top of many IT to-do lists, but the very idea covers a great deal of territory. Are the migrating services modern, or legacy? How do they communicate with one another? And perhaps most importantly, where is the data going to live?
For traditional and legacy enterprise applications, monolithic databases are the norm. A single, highly tuned instance of Oracle, DB2, or even a small MySQL cluster handles the longer term storage of user and application data, while a multitude of applications reach inside and get what they need done, perhaps even using stored procedures.
The cloud breaks this pattern. Stored procedures should be made into microservices, databases must be highly scalable, and larger data stores that contain relational information are relegated to jobs like “Data Lake” storage, off the beaten path of second-to-second transactions.
Where once there was a monolith connected to another monolith, microservices require the vivisection of those systems, and the splaying of their innards upon the public cloud, like some digital diviner reading the future atop an Aztec pyramid. The very act of deconstructing a monolith can require intense infrastructure re-architecture, and a large amount of actual software development work; the sort no developer wants to handle.
There are ways around this problem, however. Many companies offer solutions designed to help bring existing applications into a hybrid cloud model. Sirish Raghuram, CEO of Platform9, said that his company offers a way to bring Kubernetes to bear upon such systems.
“The way it works is that from the SaaS platform you can download a little agent and drop it onto these servers. That agent integrates and pairs the server infrastructure with your cloud platform and brings that under management. You can set policy saying ‘these ten servers are going to be running virtual machines, with hypervisors. These other ten servers are going to be what we call a container-visor, in other words, it’s going to run Docker containers. And these five nodes over there are going to be my storage nodes. They’re going to run block storage services. If you only have containers, Platform9 will go and do all the hard work behind the scenes, configuring Kubernetes to bring those nodes into operation,” said Raghuram.
For some services, this halfway point favored by Platform9 and VMware is a good stepping stone for monolithic applications that may be prohibitively expensive to turn into microservices. Offering the flexibility to manage virtual machines for legacy applications, and containers for modern ones from the same console means one layer of complexity for migration is at least abstracted away.
Yet at the end of the day, the real goal is to provide a path for past and future services to easily be integrated into your cloud architecture. Going whole hog requires extensive infrastructure, specifically around service discovery, load balancing, and automatic scaling. Services like Mesosphere, Cloudbolt.io, Spi.ne, and Platform9 all offer models for handling such infrastructure, behind it all is one basic principle: cloud-based applications are best without state.
Stateful applications simply don’t scale as easily as stateless ones. It’s a basic fact: if memory on one machine is filled with important information, and the machine goes down, that state is lost forever. Complex memory mirroring schemes aren’t appropriate for highly scalable applications, either, as they chew up bandwidth and slow down systems.
Instead, the easiest starting point for migrating to microservices is with the abstraction of state. Whatever that state may be, it must first be pulled out into the open and handled in another fashion. In a way, this model mirrors that of functional programming: rather than setting a variable to a value, we instead pass a value through a function, yielding a unique and new result on the other side. At no point do we overwrite the original variable’s value.
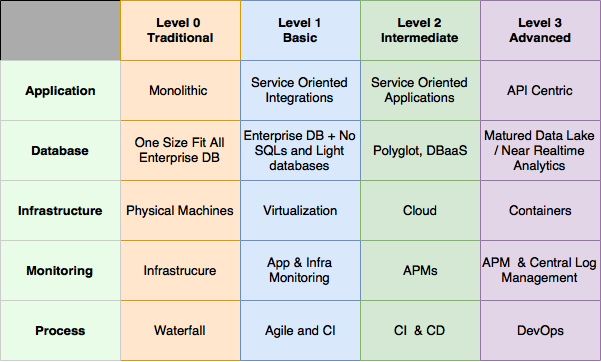
A microservices maturity model, from “Spring 5.0 Microservices,” 2nd Edition” by Rajesh R V (O’Reilly)
So too is it with stateless microservices: instead of setting variables internally to represent externally sourced data, we simply pass that data through the application, as though it were a manufacturing process. The application outputs a value based on the input, but that input should still be out there somewhere: on a message queue, in a streaming data server like Flink or Kafka, or even in a caching layer somewhere hosted out on the edge of the network.
This is, perhaps, one of the reasons streaming platforms have been growing in popularity recently: they allow for the abstraction of state from all applications, while still enabling a fast user experience on the other side of the queue.
At AWS re:Invent in November of 2016, Emerson Loureiro, senior software engineer at fashion e-commerce site Gilt, laid out an excellent path from monolith to microservice. Loureiro has since gone on to join Amazon Web Services as a software developer.
In his talk, he lays out Gilt’s software history. In 2007, the company had a monolithic Ruby on Rails application. By 2011, the Ruby application had been broken down in a series of Java services. “We did realize that a lot of those Java services, they became monoliths themselves. We broke those further down into, now, real microservices, now being written in Scala. We also wrote a ton of new services as well. We broke down our front-end apps into lots of smaller components,” said Loureiro.
Today, Gilt is running on a microservices architecture, added Loureiro. That microservices journey also yielded a move to Amazon’s cloud, along the way; the Gilt team moved to microservices independent of its move to cloud.
When the cloud move was made, the team packaged up legacy applications into virtual machines. Once all of Gilt’s applications were packaged up, they were then divided among five departments inside Gilt’s IT team, each with its own Amazon account. Each team was responsible for running its specific services, which could be migrated over quickly as they’d already been packaged up and readied to go by a central IT force.
The Gilt team organized these microservices around specific business initiatives. This meant each business group was responsible for running and maintaining its specific set of microservices. This also meant that the lines of control for, say, the accounts team, were kept inside that team. No outside developers or IT staff members were needed to fix internal accounts problems, speeding up response times for issues, and enabling the team to increase its innovative velocity.
This could also require some reorganizing of these teams, however. Each group will need its own front end, back end, and networking developers, though the numbers of each will likely vary from team to team. Loureiro advocated for teams sized to between three and five people.
However, each team is not exclusively consuming its own services. The very idea of microservices is to enable everyone in the enterprise to access the business functionality they need at any time. Thus, while individual teams control their own applications and services, they do need to interact with one another in order to consume and offer those services outside.
Derek Chiles, now senior manager of Amazon Web Services’ Worldwide Tech Leader Team, speaking with Loureiro, advocated for some best practices around discovery, to help with this type of service sharing. One method for keeping discovery sane is using conventional naming schemes for identifying services. This, he said, is the simplest, most flexible method, as it uses DNS.
Dynamic discovery is another method of handling this problem, but it does add another layer of complexity to the architecture. Systems like etcd, HashiCorp‘s Consul, and Eureka, all allow service discovery to be performed dynamically within the architecture. This does add another service and a point of failure to your architecture.
Next in the list of things to have in place is API management. While companies like Apigee (Now Google), Mulesoft, and Oracle will all sell you API gateways, there’s a lot more complexity and nuance in the space than simply putting a gateway in place. As some services will inevitably be earning money based on usage, API gateways are a great place to implement billing and usage tracking through complex metrics captured by these commercial systems, however. SLA enforcement is, naturally a portion of that as well.
The real draw for microservices is increasing enterprise software development velocity while lowering costs and reducing complexity.
Yet for most teams, starting out with a simpler approach to API management may be the best way to go. The first thing on the list to manage is traffic metering and throttling. API management at its core, is load balancing with more complex rules. To this end, teams can use open source solutions such as NGINX to handle the most basic of API management functionality.
When the migration is further along, monetization of APIs through commercial gateways may actually be needed, but many teams find that existing solutions are up to the task at a far lower cost point. The general rule of thumb we’ve seen has been that if the API directly generates revenue through usage, that’s the point where a commercial solution should enter the picture. For internal and external API traffic that is not generating business revenues, non-commercial solutions can typically handle the problems. Gateways can get pricey very quickly, as many companies charge based on traffic, so they should be a last resort.
The real draw for microservices is increasing enterprise software development velocity while lowering costs and reducing complexity. Those are very tall orders on their own, so getting all three benefits while also migrating legacy applications to the cloud can be the sort of “boil the ocean” project that chokes and IT department.
In the end, each of the benefits can be gained individually along the way: they don’t have to all come at once. Just as all of your services don’t have to be migrated at once. One of the best things about microservices is that they are loosely coupled, self-contained, and their end goal is always to be completely static code. If done right, a microservice can be perfected and left alone indefinitely, never needed updates or maintenance. That’s far easier said than done, however.
Still, any team can build anything they want, when given a microservice environment. New languages and software can be integrated into services, and kept from interfering with maintenance elsewhere. Your team can experiment with Go, Rust, Scala, or any of a dozen other interesting new languages. They can test balloon a new library, server software, or even a whole new database in a single microservice, rolling it out slowly to ensure it goes well.
Indeed, the promises of microservices are large. Getting to them simply requires a steady plan and diverse teams.
TNS Analyst Lawrence Hecht contributed to this article.